Metrics¶
This is a general package for PyTorch Metrics. These can also be used with regular non-lightning PyTorch code. Metrics are used to monitor model performance.
In this package, we provide two major pieces of functionality.
A Metric class you can use to implement metrics with built-in distributed (ddp) support which are device agnostic.
A collection of ready to use popular metrics. There are two types of metrics: Class metrics and Functional metrics.
An interface to call sklearns metrics
Example:
from pytorch_lightning.metrics.functional import accuracy
pred = torch.tensor([0, 1, 2, 3])
target = torch.tensor([0, 1, 2, 2])
# calculates accuracy across all GPUs and all Nodes used in training
accuracy(pred, target)
Warning
The metrics package is still in development! If we’re missing a metric or you find a mistake, please send a PR! to a few metrics. Please feel free to create an issue/PR if you have a proposed metric or have found a bug.
Implement a metric¶
You can implement metrics as either a PyTorch metric or a Numpy metric (It is recommended to use PyTorch metrics when possible, since Numpy metrics slow down training).
Use TensorMetric to implement native PyTorch metrics. This class
handles automated DDP syncing and converts all inputs and outputs to tensors.
Use NumpyMetric to implement numpy metrics. This class
handles automated DDP syncing and converts all inputs and outputs to tensors.
Warning
Numpy metrics might slow down your training substantially, since every metric computation requires a GPU sync to convert tensors to numpy.
TensorMetric¶
Here’s an example showing how to implement a TensorMetric
class RMSE(TensorMetric):
def forward(self, x, y):
return torch.sqrt(torch.mean(torch.pow(x-y, 2.0)))
-
class
pytorch_lightning.metrics.metric.TensorMetric(name, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricBase class for metric implementation operating directly on tensors. All inputs and outputs will be casted to tensors if necessary. Already handles DDP sync and input/output conversions.
- Parameters
NumpyMetric¶
Here’s an example showing how to implement a NumpyMetric
class RMSE(NumpyMetric):
def forward(self, x, y):
return np.sqrt(np.mean(np.power(x-y, 2.0)))
-
class
pytorch_lightning.metrics.metric.NumpyMetric(name, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricBase class for metric implementation operating on numpy arrays. All inputs will be casted to numpy if necessary and all outputs will be casted to tensors if necessary. Already handles DDP sync and input/output conversions.
- Parameters
Class Metrics¶
Class metrics can be instantiated as part of a module definition (even with just plain PyTorch).
from pytorch_lightning.metrics import Accuracy
# Plain PyTorch
class MyModule(Module):
def __init__(self):
super().__init__()
self.metric = Accuracy()
def forward(self, x, y):
y_hat = ...
acc = self.metric(y_hat, y)
# PyTorch Lightning
class MyModule(LightningModule):
def __init__(self):
super().__init__()
self.metric = Accuracy()
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = ...
acc = self.metric(y_hat, y)
These metrics even work when using distributed training:
model = MyModule()
trainer = Trainer(gpus=8, num_nodes=2)
# any metric automatically reduces across GPUs (even the ones you implement using Lightning)
trainer.fit(model)
Accuracy¶
-
class
pytorch_lightning.metrics.classification.Accuracy(num_classes=None, reduction='elementwise_mean', reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the accuracy classification score
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = Accuracy() >>> metric(pred, target) tensor(0.7500)
- Parameters
reduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass array - sum: add elementsreduce_group¶ (
Optional[Any]) – the process group to reduce metric results from DDPreduce_op¶ (
Optional[Any]) – the operation to perform for ddp reduction
AveragePrecision¶
-
class
pytorch_lightning.metrics.classification.AveragePrecision(pos_label=1, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the average precision score
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = AveragePrecision() >>> metric(pred, target) tensor(0.3333)
- Parameters
AUROC¶
-
class
pytorch_lightning.metrics.classification.AUROC(pos_label=1, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the area under curve (AUC) of the receiver operator characteristic (ROC)
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = AUROC() >>> metric(pred, target) tensor(0.3333)
- Parameters
BLEUScore¶
-
class
pytorch_lightning.metrics.nlp.BLEUScore(n_gram=4, smooth=False)[source] Bases:
pytorch_lightning.metrics.metric.MetricCalculate BLEU score of machine translated text with one or more references.
Example
>>> translate_corpus = ['the cat is on the mat'.split()] >>> reference_corpus = [['there is a cat on the mat'.split(), 'a cat is on the mat'.split()]] >>> metric = BLEUScore() >>> metric(translate_corpus, reference_corpus) tensor(0.7598)
- Parameters
ConfusionMatrix¶
-
class
pytorch_lightning.metrics.classification.ConfusionMatrix(normalize=False, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the confusion matrix C where each entry C_{i,j} is the number of observations in group i that were predicted in group j.
Example
>>> pred = torch.tensor([0, 1, 2, 2]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = ConfusionMatrix() >>> metric(pred, target) tensor([[1., 0., 0.], [0., 1., 0.], [0., 0., 2.]])
- Parameters
DiceCoefficient¶
-
class
pytorch_lightning.metrics.classification.DiceCoefficient(include_background=False, nan_score=0.0, no_fg_score=0.0, reduction='elementwise_mean', reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the dice coefficient
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> metric = DiceCoefficient() >>> metric(pred, target) tensor(0.3333)
- Parameters
include_background¶ (
bool) – whether to also compute dice for the backgroundnan_score¶ (
float) – score to return, if a NaN occurs during computation (denom zero)no_fg_score¶ (
float) – score to return, if no foreground pixel was found in targetreduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass array - sum: add elementsreduce_group¶ (
Optional[Any]) – the process group to reduce metric results from DDPreduce_op¶ (
Optional[Any]) – the operation to perform for ddp reduction
F1¶
-
class
pytorch_lightning.metrics.classification.F1(num_classes=None, reduction='elementwise_mean', reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the F1 score, which is the harmonic mean of the precision and recall. It ranges between 1 and 0, where 1 is perfect and the worst value is 0.
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = F1() >>> metric(pred, target) tensor(0.6667)
- Parameters
reduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass array - sum: add elementsreduce_group¶ (
Optional[Any]) – the process group to reduce metric results from DDPreduce_op¶ (
Optional[Any]) – the operation to perform for ddp reduction
FBeta¶
-
class
pytorch_lightning.metrics.classification.FBeta(beta, num_classes=None, reduction='elementwise_mean', reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetric- Computes the FBeta Score, which is the weighted harmonic mean of precision and recall.
It ranges between 1 and 0, where 1 is perfect and the worst value is 0.
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = FBeta(0.25) >>> metric(pred, target) tensor(0.7361)
- Parameters
beta¶ (
float) – determines the weight of recall in the combined score.reduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass array - sum: add elementsreduce_group¶ (
Optional[Any]) – the process group to reduce metric results from DDPreduce_op¶ (
Optional[Any]) – the operation to perform for DDP reduction
PrecisionRecall¶
-
class
pytorch_lightning.metrics.classification.PrecisionRecall(pos_label=1, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorCollectionMetricComputes the precision recall curve
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = PrecisionRecall() >>> prec, recall, thr = metric(pred, target) >>> prec tensor([0.3333, 0.0000, 0.0000, 1.0000]) >>> recall tensor([1., 0., 0., 0.]) >>> thr tensor([1., 2., 3.])
- Parameters
-
forward(pred, target, sample_weight=None)[source] Actual metric computation
Precision¶
-
class
pytorch_lightning.metrics.classification.Precision(num_classes=None, reduction='elementwise_mean', reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the precision score
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = Precision(num_classes=4) >>> metric(pred, target) tensor(0.7500)
- Parameters
reduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass array - sum: add elementsreduce_group¶ (
Optional[Any]) – the process group to reduce metric results from DDPreduce_op¶ (
Optional[Any]) – the operation to perform for ddp reduction
Recall¶
-
class
pytorch_lightning.metrics.classification.Recall(num_classes=None, reduction='elementwise_mean', reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the recall score
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = Recall() >>> metric(pred, target) tensor(0.6250)
- Parameters
reduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass array - sum: add elementsreduce_group¶ (
Optional[Any]) – the process group to reduce metric results from DDPreduce_op¶ (
Optional[Any]) – the operation to perform for ddp reduction
ROC¶
-
class
pytorch_lightning.metrics.classification.ROC(pos_label=1, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorCollectionMetricComputes the Receiver Operator Characteristic (ROC)
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> metric = ROC() >>> fps, tps, thresholds = metric(pred, target) >>> fps tensor([0.0000, 0.3333, 0.6667, 0.6667, 1.0000]) >>> tps tensor([0., 0., 0., 1., 1.]) >>> thresholds tensor([4., 3., 2., 1., 0.])
- Parameters
-
forward(pred, target, sample_weight=None)[source] Actual metric computation
MAE¶
-
class
pytorch_lightning.metrics.regression.MAE(reduction='elementwise_mean')[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the mean absolute loss or L1-loss.
Example
>>> pred = torch.tensor([0., 1, 2, 3]) >>> target = torch.tensor([0., 1, 2, 2]) >>> metric = MAE() >>> metric(pred, target) tensor(0.2500)
MSE¶
-
class
pytorch_lightning.metrics.regression.MSE(reduction='elementwise_mean')[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the mean squared loss.
Example
>>> pred = torch.tensor([0., 1, 2, 3]) >>> target = torch.tensor([0., 1, 2, 2]) >>> metric = MSE() >>> metric(pred, target) tensor(0.2500)
MulticlassROC¶
-
class
pytorch_lightning.metrics.classification.MulticlassROC(num_classes=None, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorCollectionMetricComputes the multiclass ROC
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> metric = MulticlassROC() >>> classes_roc = metric(pred, target) >>> metric(pred, target) ((tensor([0., 0., 1.]), tensor([0., 1., 1.]), tensor([1.8500, 0.8500, 0.0500])), (tensor([0., 0., 1.]), tensor([0., 1., 1.]), tensor([1.8500, 0.8500, 0.0500])), (tensor([0.0000, 0.3333, 1.0000]), tensor([0., 0., 1.]), tensor([1.8500, 0.8500, 0.0500])), (tensor([0.0000, 0.3333, 1.0000]), tensor([0., 0., 1.]), tensor([1.8500, 0.8500, 0.0500])))
- Parameters
-
forward(pred, target, sample_weight=None)[source] Actual metric computation
- Parameters
- Returns
A tuple consisting of one tuple per class, holding false positive rate, true positive rate and thresholds
- Return type
MulticlassPrecisionRecall¶
-
class
pytorch_lightning.metrics.classification.MulticlassPrecisionRecall(num_classes=None, reduce_group=None, reduce_op=None)[source] Bases:
pytorch_lightning.metrics.metric.TensorCollectionMetricComputes the multiclass PR Curve
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> metric = MulticlassPrecisionRecall() >>> metric(pred, target) ((tensor([1., 1.]), tensor([1., 0.]), tensor([0.8500])), (tensor([1., 1.]), tensor([1., 0.]), tensor([0.8500])), (tensor([0.2500, 0.0000, 1.0000]), tensor([1., 0., 0.]), tensor([0.0500, 0.8500])), (tensor([0.2500, 0.0000, 1.0000]), tensor([1., 0., 0.]), tensor([0.0500, 0.8500])))
- Parameters
-
forward(pred, target, sample_weight=None)[source] Actual metric computation
- Parameters
- Returns
A tuple consisting of one tuple per class, holding precision, recall and thresholds
- Return type
IoU¶
-
class
pytorch_lightning.metrics.classification.IoU(remove_bg=False, reduction='elementwise_mean')[source] Bases:
pytorch_lightning.metrics.metric.TensorMetricComputes the intersection over union.
Example
>>> pred = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0], ... [0, 0, 1, 1, 1, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0]]) >>> target = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 1, 1, 1, 0, 0], ... [0, 0, 0, 0, 0, 0, 0, 0]]) >>> metric = IoU() >>> metric(pred, target) tensor(0.7045)
- Parameters
remove_bg¶ (
bool) – Flag to state whether a background class has been included within input parameters. If true, will remove background class. If false, return IoU over all classes. Assumes that background is ‘0’ class in input tensora method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
-
forward(y_pred, y_true, sample_weight=None)[source] Actual metric calculation.
RMSE¶
-
class
pytorch_lightning.metrics.regression.RMSE(reduction='elementwise_mean')[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the root mean squared loss.
Example
>>> pred = torch.tensor([0., 1, 2, 3]) >>> target = torch.tensor([0., 1, 2, 2]) >>> metric = RMSE() >>> metric(pred, target) tensor(0.5000)
RMSLE¶
-
class
pytorch_lightning.metrics.regression.RMSLE(reduction='elementwise_mean')[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the root mean squared log loss.
Example
>>> pred = torch.tensor([0., 1, 2, 3]) >>> target = torch.tensor([0., 1, 2, 2]) >>> metric = RMSLE() >>> metric(pred, target) tensor(0.0207)
SSIM¶
-
class
pytorch_lightning.metrics.regression.SSIM(kernel_size=(11, 11), sigma=(1.5, 1.5), reduction='elementwise_mean', data_range=None, k1=0.01, k2=0.03)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes Structual Similarity Index Measure
Example
>>> pred = torch.rand([16, 1, 16, 16]) >>> target = pred * 0.75 >>> metric = SSIM() >>> metric(pred, target) tensor(0.9219)
- Parameters
kernel_size¶ (
Sequence[int]) – Size of the gaussian kernel (default: (11, 11))sigma¶ (
Sequence[float]) – Standard deviation of the gaussian kernel (default: (1.5, 1.5))reduction¶ (
str) – a method to reduce metric score over labels (default: takes the mean) Available reduction methods: - elementwise_mean: takes the mean - none: pass away - sum: add elementsdata_range¶ (
Optional[float]) – Range of the image. IfNone, it is determined from the image (max - min)
Functional Metrics¶
Functional metrics can be called anywhere (even used with just plain PyTorch).
from pytorch_lightning.metrics.functional import accuracy
pred = torch.tensor([0, 1, 2, 3])
target = torch.tensor([0, 1, 2, 2])
# calculates accuracy across all GPUs and all Nodes used in training
accuracy(pred, target)
These metrics even work when using distributed training:
class MyModule(...):
def forward(self, x, y):
return accuracy(x, y)
model = MyModule()
trainer = Trainer(gpus=8, num_nodes=2)
# any metric automatically reduces across GPUs (even the ones you implement using Lightning)
trainer.fit(model)
accuracy (F)¶
-
pytorch_lightning.metrics.functional.accuracy(pred, target, num_classes=None, reduction='elementwise_mean')[source] Computes the accuracy classification score
- Parameters
reduction¶ –
a method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
- Return type
- Returns
A Tensor with the classification score.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> accuracy(x, y) tensor(0.7500)
auc (F)¶
-
pytorch_lightning.metrics.functional.auc(x, y, reorder=True)[source] Computes Area Under the Curve (AUC) using the trapezoidal rule
- Parameters
- Return type
- Returns
Tensor containing AUC score (float)
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> auc(x, y) tensor(4.)
auroc (F)¶
-
pytorch_lightning.metrics.functional.auroc(pred, target, sample_weight=None, pos_label=1.0)[source] Compute Area Under the Receiver Operating Characteristic Curve (ROC AUC) from prediction scores
- Parameters
- Return type
- Returns
Tensor containing ROCAUC score
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> auroc(x, y) tensor(0.3333)
average_precision (F)¶
-
pytorch_lightning.metrics.functional.average_precision(pred, target, sample_weight=None, pos_label=1.0)[source] Compute average precision from prediction scores
- Parameters
- Return type
- Returns
Tensor containing average precision score
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> average_precision(x, y) tensor(0.3333)
bleu_score (F)¶
-
pytorch_lightning.metrics.functional.bleu_score(translate_corpus, reference_corpus, n_gram=4, smooth=False)[source] Calculate BLEU score of machine translated text with one or more references
- Parameters
- Return type
- Returns
Tensor with BLEU Score
Example
>>> translate_corpus = ['the cat is on the mat'.split()] >>> reference_corpus = [['there is a cat on the mat'.split(), 'a cat is on the mat'.split()]] >>> bleu_score(translate_corpus, reference_corpus) tensor(0.7598)
confusion_matrix (F)¶
-
pytorch_lightning.metrics.functional.confusion_matrix(pred, target, normalize=False)[source] Computes the confusion matrix C where each entry C_{i,j} is the number of observations in group i that were predicted in group j.
- Parameters
- Return type
- Returns
Tensor, confusion matrix C [num_classes, num_classes ]
Example
>>> x = torch.tensor([1, 2, 3]) >>> y = torch.tensor([0, 2, 3]) >>> confusion_matrix(x, y) tensor([[0., 1., 0., 0.], [0., 0., 0., 0.], [0., 0., 1., 0.], [0., 0., 0., 1.]])
dice_score (F)¶
-
pytorch_lightning.metrics.functional.dice_score(pred, target, bg=False, nan_score=0.0, no_fg_score=0.0, reduction='elementwise_mean')[source] Compute dice score from prediction scores
- Parameters
bg¶ (
bool) – whether to also compute dice for the backgroundnan_score¶ (
float) – score to return, if a NaN occurs during computationno_fg_score¶ (
float) – score to return, if no foreground pixel was found in targeta method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
- Return type
- Returns
Tensor containing dice score
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> dice_score(pred, target) tensor(0.3333)
f1_score (F)¶
-
pytorch_lightning.metrics.functional.f1_score(pred, target, num_classes=None, reduction='elementwise_mean')[source] Computes the F1-score (a.k.a F-measure), which is the harmonic mean of the precision and recall. It ranges between 1 and 0, where 1 is perfect and the worst value is 0.
- Parameters
reduction¶ –
a method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements.
- Return type
- Returns
Tensor containing F1-score
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> f1_score(x, y) tensor(0.6667)
fbeta_score (F)¶
-
pytorch_lightning.metrics.functional.fbeta_score(pred, target, beta, num_classes=None, reduction='elementwise_mean')[source] Computes the F-beta score which is a weighted harmonic mean of precision and recall. It ranges between 1 and 0, where 1 is perfect and the worst value is 0.
- Parameters
beta¶ (
float) – weights recall when combining the score. beta < 1: more weight to precision. beta > 1 more weight to recall beta = 0: only precision beta -> inf: only recalla method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements.
- Return type
- Returns
Tensor with the value of F-score. It is a value between 0-1.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> fbeta_score(x, y, 0.2) tensor(0.7407)
multiclass_precision_recall_curve (F)¶
-
pytorch_lightning.metrics.functional.multiclass_precision_recall_curve(pred, target, sample_weight=None, num_classes=None)[source] Computes precision-recall pairs for different thresholds given a multiclass scores.
- Parameters
- Return type
- Returns
number of classes, precision, recall, thresholds
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> nb_classes, precision, recall, thresholds = multiclass_precision_recall_curve(pred, target) >>> nb_classes (tensor([1., 1.]), tensor([1., 0.]), tensor([0.8500])) >>> precision (tensor([1., 1.]), tensor([1., 0.]), tensor([0.8500])) >>> recall (tensor([0.2500, 0.0000, 1.0000]), tensor([1., 0., 0.]), tensor([0.0500, 0.8500])) >>> thresholds (tensor([0.2500, 0.0000, 1.0000]), tensor([1., 0., 0.]), tensor([0.0500, 0.8500]))
multiclass_roc (F)¶
-
pytorch_lightning.metrics.functional.multiclass_roc(pred, target, sample_weight=None, num_classes=None)[source] Computes the Receiver Operating Characteristic (ROC) for multiclass predictors.
- Parameters
- Return type
- Returns
returns roc for each class. Number of classes, false-positive rate (fpr), true-positive rate (tpr), thresholds
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> multiclass_roc(pred, target) ((tensor([0., 0., 1.]), tensor([0., 1., 1.]), tensor([1.8500, 0.8500, 0.0500])), (tensor([0., 0., 1.]), tensor([0., 1., 1.]), tensor([1.8500, 0.8500, 0.0500])), (tensor([0.0000, 0.3333, 1.0000]), tensor([0., 0., 1.]), tensor([1.8500, 0.8500, 0.0500])), (tensor([0.0000, 0.3333, 1.0000]), tensor([0., 0., 1.]), tensor([1.8500, 0.8500, 0.0500])))
precision (F)¶
-
pytorch_lightning.metrics.functional.precision(pred, target, num_classes=None, reduction='elementwise_mean')[source] Computes precision score.
- Parameters
a method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
- Return type
- Returns
Tensor with precision.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> precision(x, y) tensor(0.7500)
precision_recall (F)¶
-
pytorch_lightning.metrics.functional.precision_recall(pred, target, num_classes=None, reduction='elementwise_mean')[source] Computes precision and recall for different thresholds
- Parameters
a method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
- Return type
- Returns
Tensor with precision and recall
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> precision_recall(x, y) (tensor(0.7500), tensor(0.6250))
precision_recall_curve (F)¶
-
pytorch_lightning.metrics.functional.precision_recall_curve(pred, target, sample_weight=None, pos_label=1.0)[source] Computes precision-recall pairs for different thresholds.
- Parameters
- Return type
- Returns
precision, recall, thresholds
Example
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 2, 2]) >>> precision, recall, thresholds = precision_recall_curve(pred, target) >>> precision tensor([0.3333, 0.0000, 0.0000, 1.0000]) >>> recall tensor([1., 0., 0., 0.]) >>> thresholds tensor([1, 2, 3])
recall (F)¶
-
pytorch_lightning.metrics.functional.recall(pred, target, num_classes=None, reduction='elementwise_mean')[source] Computes recall score.
- Parameters
a method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
- Return type
- Returns
Tensor with recall.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> recall(x, y) tensor(0.6250)
roc (F)¶
-
pytorch_lightning.metrics.functional.roc(pred, target, sample_weight=None, pos_label=1.0)[source] Computes the Receiver Operating Characteristic (ROC). It assumes classifier is binary.
- Parameters
- Return type
- Returns
false-positive rate (fpr), true-positive rate (tpr), thresholds
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> fpr, tpr, thresholds = roc(x, y) >>> fpr tensor([0.0000, 0.3333, 0.6667, 0.6667, 1.0000]) >>> tpr tensor([0., 0., 0., 1., 1.]) >>> thresholds tensor([4, 3, 2, 1, 0])
stat_scores (F)¶
-
pytorch_lightning.metrics.functional.stat_scores(pred, target, class_index, argmax_dim=1)[source] Calculates the number of true positive, false positive, true negative and false negative for a specific class
- Parameters
- Return type
- Returns
True Positive, False Positive, True Negative, False Negative, Support
Example
>>> x = torch.tensor([1, 2, 3]) >>> y = torch.tensor([0, 2, 3]) >>> tp, fp, tn, fn, sup = stat_scores(x, y, class_index=1) >>> tp, fp, tn, fn, sup (tensor(0), tensor(1), tensor(2), tensor(0), tensor(0))
iou (F)¶
-
pytorch_lightning.metrics.functional.iou(pred, target, num_classes=None, remove_bg=False, reduction='elementwise_mean')[source] Intersection over union, or Jaccard index calculation.
- Parameters
num_classes¶ (
Optional[int]) – Optionally specify the number of classesremove_bg¶ (
bool) – Flag to state whether a background class has been included within input parameters. If true, will remove background class. If false, return IoU over all classes Assumes that background is ‘0’ class in input tensora method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass array
sum: add elements
- Returns
Tensor containing single value if reduction is ‘elementwise_mean’, or number of classes if reduction is ‘none’
- Return type
IoU score
Example
>>> target = torch.randint(0, 1, (10, 25, 25)) >>> pred = torch.tensor(target) >>> pred[2:5, 7:13, 9:15] = 1 - pred[2:5, 7:13, 9:15] >>> iou(pred, target) tensor(0.4914)
mse (F)¶
-
pytorch_lightning.metrics.functional.mse(pred, target, reduction='elementwise_mean')[source] Computes mean squared error
- Parameters
- Return type
- Returns
Tensor with MSE
Example
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> mse(x, y) tensor(0.2500)
rmse (F)¶
-
pytorch_lightning.metrics.functional.rmse(pred, target, reduction='elementwise_mean')[source] Computes root mean squared error
- Parameters
- Return type
- Returns
Tensor with RMSE
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> rmse(x, y) tensor(0.5000)
mae (F)¶
-
pytorch_lightning.metrics.functional.mae(pred, target, reduction='elementwise_mean')[source] Computes mean absolute error
- Parameters
- Return type
- Returns
Tensor with MAE
Example
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> mae(x, y) tensor(0.2500)
rmsle (F)¶
-
pytorch_lightning.metrics.functional.rmsle(pred, target, reduction='elementwise_mean')[source] Computes root mean squared log error
- Parameters
- Return type
- Returns
Tensor with RMSLE
Example
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> rmsle(x, y) tensor(0.0207)
psnr (F)¶
-
pytorch_lightning.metrics.functional.psnr(pred, target, data_range=None, base=10.0, reduction='elementwise_mean')[source] Computes the peak signal-to-noise ratio
- Parameters
- Return type
- Returns
Tensor with PSNR score
Example
>>> from pytorch_lightning.metrics.regression import PSNR >>> pred = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) >>> target = torch.tensor([[3.0, 2.0], [1.0, 0.0]]) >>> metric = PSNR() >>> metric(pred, target) tensor(2.5527)
ssim (F)¶
-
pytorch_lightning.metrics.functional.ssim(pred, target, kernel_size=(11, 11), sigma=(1.5, 1.5), reduction='elementwise_mean', data_range=None, k1=0.01, k2=0.03)[source] Computes Structual Similarity Index Measure
- Parameters
kernel_size¶ (
Sequence[int]) – size of the gaussian kernel (default: (11, 11))sigma¶ (
Sequence[float]) – Standard deviation of the gaussian kernel (default: (1.5, 1.5))a method to reduce metric score over labels (default: takes the mean) Available reduction methods:
elementwise_mean: takes the mean
none: pass away
sum: add elements
data_range¶ (
Optional[float]) – Range of the image. IfNone, it is determined from the image (max - min)
- Return type
- Returns
Tensor with SSIM score
Example
>>> pred = torch.rand([16, 1, 16, 16]) >>> target = pred * 0.75 >>> ssim(pred, target) tensor(0.9219)
stat_scores_multiple_classes (F)¶
-
pytorch_lightning.metrics.functional.stat_scores_multiple_classes(pred, target, num_classes=None, argmax_dim=1, reduction='none')[source] Calculates the number of true postive, false postive, true negative and false negative for each class
- Parameters
- Return type
- Returns
True Positive, False Positive, True Negative, False Negative, Support
Example
>>> x = torch.tensor([1, 2, 3]) >>> y = torch.tensor([0, 2, 3]) >>> tps, fps, tns, fns, sups = stat_scores_multiple_classes(x, y) >>> tps tensor([0., 0., 1., 1.]) >>> fps tensor([0., 1., 0., 0.]) >>> tns tensor([2., 2., 2., 2.]) >>> fns tensor([1., 0., 0., 0.]) >>> sups tensor([1., 0., 1., 1.])
Metric pre-processing¶
to_categorical (F)¶
-
pytorch_lightning.metrics.functional.to_categorical(tensor, argmax_dim=1)[source] Converts a tensor of probabilities to a dense label tensor
- Parameters
- Return type
- Returns
A tensor with categorical labels [N, d2, …]
Example
>>> x = torch.tensor([[0.2, 0.5], [0.9, 0.1]]) >>> to_categorical(x) tensor([1, 0])
to_onehot (F)¶
-
pytorch_lightning.metrics.functional.to_onehot(tensor, num_classes=None)[source] Converts a dense label tensor to one-hot format
- Parameters
- Output:
A sparse label tensor with shape [N, C, d1, d2, …]
Example
>>> x = torch.tensor([1, 2, 3]) >>> to_onehot(x) tensor([[0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
- Return type
Sklearn interface¶
Lightning supports sklearns metrics module as a backend for calculating metrics. Sklearns metrics are well tested and robust, but requires conversion between pytorch and numpy thus may slow down your computations.
To use the sklearn backend of metrics simply import as
import pytorch_lightning.metrics.sklearns import plm
metric = plm.Accuracy(normalize=True)
val = metric(pred, target)
Each converted sklearn metric comes has the same interface as its original counterpart (e.g. accuracy takes the additional normalize keyword). Like the native Lightning metrics, these converted sklearn metrics also come with built-in distributed (ddp) support.
SklearnMetric (sk)¶
-
pytorch_lightning.metrics.sklearns.SklearnMetric(metric_name, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM, **kwargs)[source] Bridge between PyTorch Lightning and scikit-learn metrics
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Note
The order of targets and predictions may be different from the order typically used in PyTorch
Accuracy (sk)¶
-
pytorch_lightning.metrics.sklearns.Accuracy(normalize=True, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the Accuracy Score
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = Accuracy() >>> metric(y_pred, y_true) tensor([0.7500])
AUC (sk)¶
-
pytorch_lightning.metrics.sklearns.AUC(reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the Area Under the Curve using the trapoezoidal rule
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = AUC() >>> metric(y_pred, y_true) tensor([4.])
AveragePrecision (sk)¶
-
pytorch_lightning.metrics.sklearns.AveragePrecision(average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the average precision (AP) score.
BalancedAccuracy (sk)¶
-
pytorch_lightning.metrics.sklearns.BalancedAccuracy(adjusted=False, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute the balanced accuracy score
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0, 0, 0, 1]) >>> y_true = torch.tensor([0, 0, 1, 1]) >>> metric = BalancedAccuracy() >>> metric(y_pred, y_true) tensor([0.7500])
CohenKappaScore (sk)¶
-
pytorch_lightning.metrics.sklearns.CohenKappaScore(labels=None, weights=None, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates Cohens kappa: a statitic that measures inter-annotator agreement
Example
>>> y_pred = torch.tensor([1, 2, 0, 2]) >>> y_true = torch.tensor([2, 2, 2, 1]) >>> metric = CohenKappaScore() >>> metric(y_pred, y_true) tensor([-0.3333])
ConfusionMatrix (sk)¶
-
pytorch_lightning.metrics.sklearns.ConfusionMatrix(labels=None, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute confusion matrix to evaluate the accuracy of a classification By definition a confusion matrix
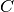 is such that
is such that 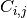 is equal to the number of observations known to be in group
is equal to the number of observations known to be in group 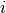 but
predicted to be in group
but
predicted to be in group 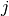 .
.Example
>>> y_pred = torch.tensor([0, 1, 2, 1]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = ConfusionMatrix() >>> metric(y_pred, y_true) tensor([[1., 0., 0.], [0., 1., 0.], [0., 1., 1.]])
DCG (sk)¶
-
pytorch_lightning.metrics.sklearns.DCG(k=None, log_base=2, ignore_ties=False, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute discounted cumulative gain
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_score = torch.tensor([[.1, .2, .3, 4, 70]]) >>> y_true = torch.tensor([[10, 0, 0, 1, 5]]) >>> metric = DCG() >>> metric(y_score, y_true) tensor([9.4995])
F1 (sk)¶
-
pytorch_lightning.metrics.sklearns.F1(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute the F1 score, also known as balanced F-score or F-measure The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal. The formula for the F1 score is:
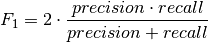
In the multi-class and multi-label case, this is the weighted average of the F1 score of each class.
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = F1() >>> metric(y_pred, y_true) tensor([0.6667])
- References
FBeta (sk)¶
-
pytorch_lightning.metrics.sklearns.FBeta(beta, labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute the F-beta score. The beta parameter determines the weight of precision in the combined score.
beta < 1lends more weight to precision, whilebeta > 1favors recall (beta -> 0considers only precision,beta -> infonly recall).Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = FBeta(beta=0.25) >>> metric(y_pred, y_true) tensor([0.7361])
References
[1] R. Baeza-Yates and B. Ribeiro-Neto (2011). Modern Information Retrieval. Addison Wesley, pp. 327-328.
Hamming (sk)¶
-
pytorch_lightning.metrics.sklearns.Hamming(reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Computes the average hamming loss
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([1, 1, 2, 3]) >>> metric = Hamming() >>> metric(y_pred, y_true) tensor([0.2500])
Hinge (sk)¶
-
pytorch_lightning.metrics.sklearns.Hinge(labels=None, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Computes the average hinge loss
Example
>>> pred_decision = torch.tensor([-2.17, -0.97, -0.19, -0.43]) >>> y_true = torch.tensor([1, 1, 0, 0]) >>> metric = Hinge() >>> metric(pred_decision, y_true) tensor([1.6300])
Jaccard (sk)¶
-
pytorch_lightning.metrics.sklearns.Jaccard(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates jaccard similarity coefficient score
Example
>>> y_pred = torch.tensor([1, 1, 1]) >>> y_true = torch.tensor([0, 1, 1]) >>> metric = Jaccard() >>> metric(y_pred, y_true) tensor([0.3333])
Precision (sk)¶
-
pytorch_lightning.metrics.sklearns.Precision(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute the precision The precision is the ratio
tp / (tp + fp)wheretpis the number of true positives andfpthe number of false positives. The precision is intuitively the ability of the classifier not to label as positive a sample that is negative. The best value is 1 and the worst value is 0.Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = Precision() >>> metric(y_pred, y_true) tensor([0.7500])
Recall (sk)¶
-
pytorch_lightning.metrics.sklearns.Recall(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute the recall The recall is the ratio
tp / (tp + fn)wheretpis the number of true positives andfnthe number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples. The best value is 1 and the worst value is 0.Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = Recall() >>> metric(y_pred, y_true) tensor([0.6250])
PrecisionRecallCurve (sk)¶
-
pytorch_lightning.metrics.sklearns.PrecisionRecallCurve(pos_label=1, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute precision-recall pairs for different probability thresholds
Note
This implementation is restricted to the binary classification task.
The precision is the ratio
tp / (tp + fp)wheretpis the number of true positives andfpthe number of false positives. The precision is intuitively the ability of the classifier not to label as positive a sample that is negative. The recall is the ratiotp / (tp + fn)wheretpis the number of true positives andfnthe number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples. The last precision and recall values are 1. and 0. respectively and do not have a corresponding threshold. This ensures that the graph starts on the x axis.
ROC (sk)¶
-
pytorch_lightning.metrics.sklearns.ROC(pos_label=1, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute Receiver operating characteristic (ROC)
Note
this implementation is restricted to the binary classification task.
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = ROC() >>> fps, tps = metric(y_pred, y_true) >>> fps tensor([0.0000, 0.3333, 0.6667, 0.6667, 1.0000]) >>> tps tensor([0., 0., 0., 1., 1.])
References
AUROC (sk)¶
-
pytorch_lightning.metrics.sklearns.AUROC(average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute Area Under the Curve (AUC) from prediction scores
Note
this implementation is restricted to the binary classification task or multilabel classification task in label indicator format.
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
ExplainedVariance (sk)¶
-
pytorch_lightning.metrics.sklearns.ExplainedVariance(multioutput='variance_weighted', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates explained variance score
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2.5, 0.0, 2, 8]) >>> y_true = torch.tensor([3, -0.5, 2, 7]) >>> metric = ExplainedVariance() >>> metric(y_pred, y_true) tensor([0.9572])
MeanAbsoluteError (sk)¶
-
pytorch_lightning.metrics.sklearns.MeanAbsoluteError(multioutput='uniform_average', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute absolute error regression loss
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2.5, 0.0, 2, 8]) >>> y_true = torch.tensor([3, -0.5, 2, 7]) >>> metric = MeanAbsoluteError() >>> metric(y_pred, y_true) tensor([0.5000])
MeanSquaredError (sk)¶
-
pytorch_lightning.metrics.sklearns.MeanSquaredError(multioutput='uniform_average', squared=False, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Compute mean squared error loss
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2.5, 0.0, 2, 8]) >>> y_true = torch.tensor([3, -0.5, 2, 7]) >>> metric = MeanSquaredError() >>> metric(y_pred, y_true) tensor([0.3750]) >>> metric = MeanSquaredError(squared=True) >>> metric(y_pred, y_true) tensor([0.6124])
MeanSquaredLogError (sk)¶
-
pytorch_lightning.metrics.sklearns.MeanSquaredLogError(multioutput='uniform_average', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the mean squared log error
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2.5, 5, 4, 8]) >>> y_true = torch.tensor([3, 5, 2.5, 7]) >>> metric = MeanSquaredLogError() >>> metric(y_pred, y_true) tensor([0.0397])
MedianAbsoluteError (sk)¶
-
pytorch_lightning.metrics.sklearns.MedianAbsoluteError(multioutput='uniform_average', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the median absolute error
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2.5, 0.0, 2, 8]) >>> y_true = torch.tensor([3, -0.5, 2, 7]) >>> metric = MedianAbsoluteError() >>> metric(y_pred, y_true) tensor([0.5000])
R2Score (sk)¶
-
pytorch_lightning.metrics.sklearns.R2Score(multioutput='uniform_average', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the R^2 score also known as coefficient of determination
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2.5, 0.0, 2, 8]) >>> y_true = torch.tensor([3, -0.5, 2, 7]) >>> metric = R2Score() >>> metric(y_pred, y_true) tensor([0.9486])
MeanPoissonDeviance (sk)¶
-
pytorch_lightning.metrics.sklearns.MeanPoissonDeviance(reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the mean poisson deviance regression loss
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2, 0.5, 1, 4]) >>> y_true = torch.tensor([0.5, 0.5, 2., 2.]) >>> metric = MeanPoissonDeviance() >>> metric(y_pred, y_true) tensor([0.9034])
MeanGammaDeviance (sk)¶
-
pytorch_lightning.metrics.sklearns.MeanGammaDeviance(reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the mean gamma deviance regression loss
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0.5, 0.5, 2., 2.]) >>> y_true = torch.tensor([2, 0.5, 1, 4]) >>> metric = MeanGammaDeviance() >>> metric(y_pred, y_true) tensor([1.0569])
MeanTweedieDeviance (sk)¶
-
pytorch_lightning.metrics.sklearns.MeanTweedieDeviance(power=0, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source] Calculates the mean tweedie deviance regression loss
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([2, 0.5, 1, 4]) >>> y_true = torch.tensor([0.5, 0.5, 2., 2.]) >>> metric = MeanTweedieDeviance() >>> metric(y_pred, y_true) tensor([1.8125])
