Quick Start¶
PyTorch Lightning is nothing more than organized PyTorch code. Once you’ve organized it into a LightningModule, it automates most of the training for you.
To illustrate, here’s the typical PyTorch project structure organized in a LightningModule.
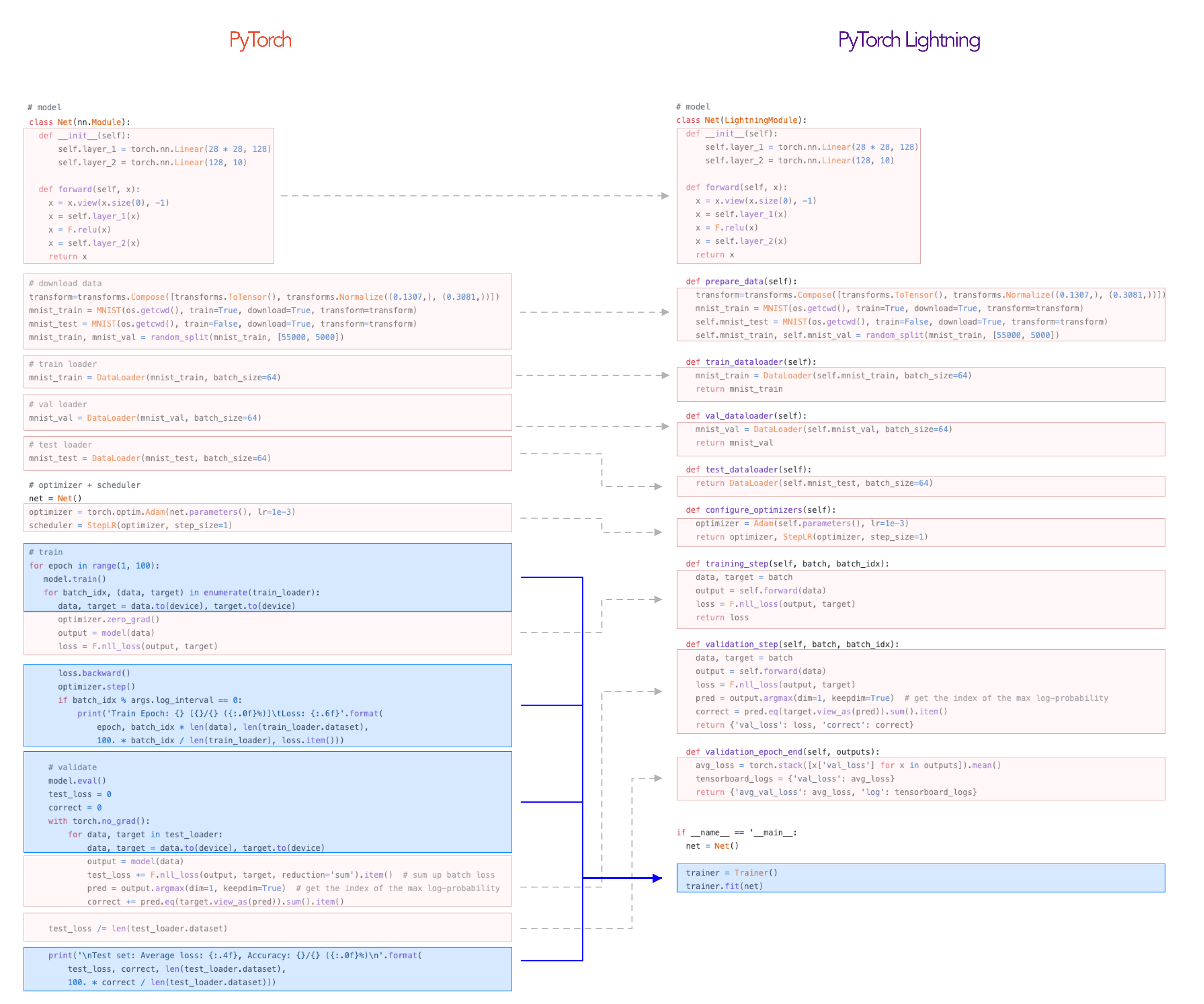
Step 1: Define a LightningModule¶
import os
import torch
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
from pytorch_lightning.core.lightning import LightningModule
class LitModel(LightningModule):
def __init__(self):
super().__init__()
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
tensorboard_logs = {'train_loss': loss}
return {'loss': loss, 'log': tensorboard_logs}
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
def train_dataloader(self):
dataset = MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor())
loader = DataLoader(dataset, batch_size=32, num_workers=4, shuffle=True)
return loader
Step 2: Fit with a Trainer¶
from pytorch_lightning import Trainer
model = LitModel()
# most basic trainer, uses good defaults
trainer = Trainer(gpus=8, num_nodes=1)
trainer.fit(model)
Under the hood, lightning does (in high-level pseudocode):
model = LitModel()
torch.set_grad_enabled(True)
model.train()
train_dataloader = model.train_dataloader()
optimizer = model.configure_optimizers()
for epoch in epochs:
train_outs = []
for batch in train_dataloader:
loss = model.training_step(batch)
loss.backward()
train_outs.append(loss.detach())
optimizer.step()
optimizer.zero_grad()
# optional for logging, etc...
model.training_epoch_end(train_outs)
Validation loop¶
To also add a validation loop add the following functions
class LitModel(LightningModule):
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
return {'val_loss': F.cross_entropy(y_hat, y)}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss}
return {'val_loss': avg_loss, 'log': tensorboard_logs}
def val_dataloader(self):
# TODO: do a real train/val split
dataset = MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor())
loader = DataLoader(dataset, batch_size=32, num_workers=4)
return loader
And now the trainer will call the validation loop automatically
# most basic trainer, uses good defaults
trainer = Trainer(gpus=8, num_nodes=1)
trainer.fit(model)
Under the hood in pseudocode, lightning does the following:
# ...
for batch in train_dataloader:
loss = model.training_step()
loss.backward()
# ...
if validate_at_some_point:
torch.set_grad_enabled(False)
model.eval()
val_outs = []
for val_batch in model.val_dataloader:
val_out = model.validation_step(val_batch)
val_outs.append(val_out)
model.validation_epoch_end(val_outs)
torch.set_grad_enabled(True)
model.train()
The beauty of Lightning is that it handles the details of when to validate, when to call .eval(), turning off gradients, detaching graphs, making sure you don’t enable shuffle for val, etc…
Note
Lightning removes all the million details you need to remember during research
Test loop¶
You might also need a test loop
class LitModel(LightningModule):
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
return {'test_loss': F.cross_entropy(y_hat, y)}
def test_epoch_end(self, outputs):
avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean()
tensorboard_logs = {'test_loss': avg_loss}
return {'avg_test_loss': avg_loss, 'log': tensorboard_logs}
def test_dataloader(self):
# TODO: do a real train/val split
dataset = MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor())
loader = DataLoader(dataset, batch_size=32, num_workers=4)
return loader
However, this time you need to specifically call test (this is done so you don’t use the test set by mistake)
# OPTION 1:
# test after fit
trainer.fit(model)
trainer.test()
# OPTION 2:
# test after loading weights
model = LitModel.load_from_checkpoint(PATH)
trainer = Trainer(tpu_cores=1)
trainer.test()
Again, under the hood, lightning does the following in (pseudocode):
torch.set_grad_enabled(False)
model.eval()
test_outs = []
for test_batch in model.test_dataloader:
test_out = model.test_step(val_batch)
test_outs.append(test_out)
model.test_epoch_end(test_outs)
Datasets¶
If you don’t want to define the datasets as part of the LightningModule, just pass them into fit instead.
# pass in datasets if you want.
train_dataloader = DataLoader(dataset, batch_size=32, num_workers=4)
val_dataloader, test_dataloader = ...
trainer = Trainer(gpus=8, num_nodes=1)
trainer.fit(model, train_dataloader, val_dataloader)
trainer.test(test_dataloader=test_dataloader)
The advantage of this method is the ability to reuse models for different datasets. The disadvantage is that for research it makes readability and reproducibility more difficult. This is why we recommend to define the datasets in the LightningModule if you’re doing research, but use the method above for production models or for prediction tasks.
Why do you need Lightning?¶
Notice the code above has nothing about .cuda() or 16-bit or early stopping or logging, etc… This is where Lightning adds a ton of value.
Without changing a SINGLE line of your code, you can now do the following with the above code
# train on TPUs using 16 bit precision with early stopping
# using only half the training data and checking validation every quarter of a training epoch
trainer = Trainer(
tpu_cores=8,
precision=16,
early_stop_checkpoint=True,
limit_train_batches=0.5,
val_check_interval=0.25
)
# train on 256 GPUs
trainer = Trainer(
gpus=8,
num_nodes=32
)
# train on 1024 CPUs across 128 machines
trainer = Trainer(
num_processes=8,
num_nodes=128
)
And the best part is that your code is STILL just PyTorch… meaning you can do anything you would normally do.
model = LitModel()
model.eval()
y_hat = model(x)
model.anything_you_can_do_with_pytorch()
Summary¶
In short, by refactoring your PyTorch code:
You STILL keep pure PyTorch.
You DON’t lose any flexibility.
You can get rid of all of your boilerplate.
You make your code generalizable to any hardware.
Your code is now readable and easier to reproduce (ie: you help with the reproducibility crisis).
Your LightningModule is still just a pure PyTorch module.
