Trainer¶
Once you’ve organized your PyTorch code into a LightningModule, the Trainer automates everything else.
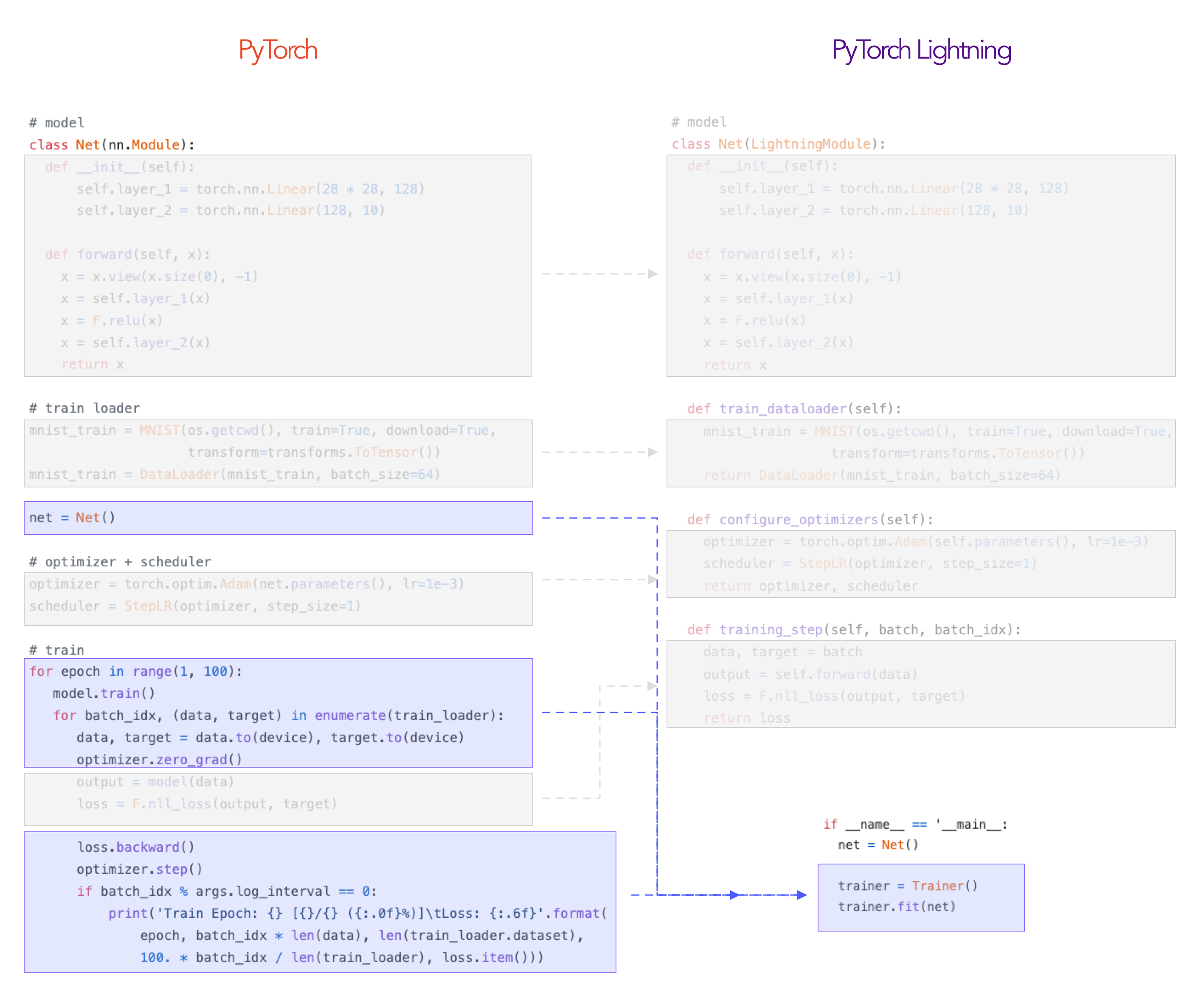
This abstraction achieves the following:
You maintain control over all aspects via PyTorch code without an added abstraction.
The trainer uses best practices embedded by contributors and users from top AI labs such as Facebook AI Research, NYU, MIT, Stanford, etc…
The trainer allows overriding any key part that you don’t want automated.
Basic use¶
This is the basic use of the trainer:
model = MyLightningModule()
trainer = Trainer()
trainer.fit(model)
Best Practices¶
For cluster computing, it’s recommended you structure your main.py file this way
from argparse import ArgumentParser
def main(hparams):
model = LightningModule()
trainer = Trainer(gpus=hparams.gpus)
trainer.fit(model)
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--gpus', default=None)
args = parser.parse_args()
main(args)
So you can run it like so:
python main.py --gpus 2
Note
If you want to stop a training run early, you can press “Ctrl + C” on your keyboard. The trainer will catch the KeyboardInterrupt and attempt a graceful shutdown, including running callbacks such as on_train_end. The trainer object will also set an attribute interrupted to True in such cases. If you have a callback which shuts down compute resources, for example, you can conditionally run the shutdown logic for only uninterrupted runs.
Testing¶
Once you’re done training, feel free to run the test set! (Only right before publishing your paper or pushing to production)
trainer.test()
Deployment / prediction¶
You just trained a LightningModule which is also just a torch.nn.Module. Use it to do whatever!
# load model
pretrained_model = LightningModule.load_from_checkpoint(PATH)
pretrained_model.freeze()
# use it for finetuning
def forward(self, x):
features = pretrained_model(x)
classes = classifier(features)
# or for prediction
out = pretrained_model(x)
api_write({'response': out}
You may wish to run the model on a variety of devices. Instead of moving the data
manually to the correct device, decorate the forward method (or any other method you use for inference)
with auto_move_data() and Lightning will take care of the rest.
Reproducibility¶
To ensure full reproducibility from run to run you need to set seeds for pseudo-random generators,
and set deterministic` flag in Trainer.
Example:
from pytorch_lightning import Trainer, seed_everything
seed_everything(42)
# sets seeds for numpy, torch, python.random and PYTHONHASHSEED.
model = Model()
trainer = Trainer(deterministic=True)
Trainer flags¶
accumulate_grad_batches¶
Accumulates grads every k batches or as set up in the dict.
# default used by the Trainer (no accumulation)
trainer = Trainer(accumulate_grad_batches=1)
Example:
# accumulate every 4 batches (effective batch size is batch*4)
trainer = Trainer(accumulate_grad_batches=4)
# no accumulation for epochs 1-4. accumulate 3 for epochs 5-10. accumulate 20 after that
trainer = Trainer(accumulate_grad_batches={5: 3, 10: 20})
amp_level¶
The optimization level to use (O1, O2, etc…) for 16-bit GPU precision (using NVIDIA apex under the hood).
Check NVIDIA apex docs for level
Example:
# default used by the Trainer
trainer = Trainer(amp_level='O2')
auto_scale_batch_size¶
Automatically tries to find the largest batch size that fits into memory, before any training.
# default used by the Trainer (no scaling of batch size)
trainer = Trainer(auto_scale_batch_size=None)
# run batch size scaling, result overrides hparams.batch_size
trainer = Trainer(auto_scale_batch_size='binsearch')
auto_lr_find¶
Runs a learning rate finder algorithm (see this paper) before any training, to find optimal initial learning rate.
# default used by the Trainer (no learning rate finder)
trainer = Trainer(auto_lr_find=False)
Example:
# run learning rate finder, results override hparams.learning_rate
trainer = Trainer(auto_lr_find=True)
# run learning rate finder, results override hparams.my_lr_arg
trainer = Trainer(auto_lr_find='my_lr_arg')
Note
See the learning rate finder guide
benchmark¶
If true enables cudnn.benchmark. This flag is likely to increase the speed of your system if your input sizes don’t change. However, if it does, then it will likely make your system slower.
The speedup comes from allowing the cudnn auto-tuner to find the best algorithm for the hardware [see discussion here].
Example:
# default used by the Trainer
trainer = Trainer(benchmark=False)
deterministic¶
If true enables cudnn.deterministic.
Might make your system slower, but ensures reproducibility.
Also sets $HOROVOD_FUSION_THRESHOLD=0.
For more info check [pytorch docs].
Example:
# default used by the Trainer
trainer = Trainer(deterministic=False)
callbacks¶
Add a list of user defined callbacks. These callbacks DO NOT replace the explicit callbacks (loggers, EarlyStopping or ModelCheckpoint).
Note
Only user defined callbacks (ie: Not EarlyStopping or ModelCheckpoint)
# a list of callbacks
callbacks = [PrintCallback()]
trainer = Trainer(callbacks=callbacks)
Example:
from pytorch_lightning.callbacks import Callback
class PrintCallback(Callback):
def on_train_start(self, trainer, pl_module):
print("Training is started!")
def on_train_end(self, trainer, pl_module):
print("Training is done.")
check_val_every_n_epoch¶
Check val every n train epochs.
Example:
# default used by the Trainer
trainer = Trainer(check_val_every_n_epoch=1)
# run val loop every 10 training epochs
trainer = Trainer(check_val_every_n_epoch=10)
checkpoint_callback¶
Callback for checkpointing.
from pytorch_lightning.callbacks import ModelCheckpoint
trainer = Trainer(checkpoint_callback=ModelCheckpoint())
Example:
from pytorch_lightning.callbacks import ModelCheckpoint
# default used by the Trainer
checkpoint_callback = ModelCheckpoint(
filepath=os.getcwd(),
save_top_k=True,
verbose=True,
monitor='val_loss',
mode='min',
prefix=''
)
default_root_dir¶
Default path for logs and weights when no logger
or pytorch_lightning.callbacks.ModelCheckpoint callback passed.
On certain clusters you might want to separate where logs and checkpoints
are stored. If you don’t then use this method for convenience.
Example:
# default used by the Trainer
trainer = Trainer(default_root_path=os.getcwd())
distributed_backend¶
The distributed backend to use.
(
`dp`) is DataParallel (split batch among GPUs of same machine)(
`ddp`) is DistributedDataParallel (each gpu on each node trains, and syncs grads)(
`ddp_cpu`) is DistributedDataParallel on CPU (same as ddp, but does not use GPUs. Useful for multi-node CPU training or single-node debugging. Note that this will not give a speedup on a single node, since Torch already makes effient use of multiple CPUs on a single machine.)- (
`ddp2`) dp on node, ddp across nodes. Useful for things like increasing the number of negative samples
- (
# default used by the Trainer
trainer = Trainer(distributed_backend=None)
Example:
# dp = DataParallel
trainer = Trainer(gpus=2, distributed_backend='dp')
# ddp = DistributedDataParallel
trainer = Trainer(gpus=2, num_nodes=2, distributed_backend='ddp')
# ddp2 = DistributedDataParallel + dp
trainer = Trainer(gpus=2, num_nodes=2, distributed_backend='ddp2')
Note
this option does not apply to TPU. TPUs use `ddp` by default (over each core)
early_stop_callback¶
Callback for early stopping.
early_stop_callback (pytorch_lightning.callbacks.EarlyStopping)
True: A default callback monitoring'val_loss'is created.Will raise an error if
'val_loss'is not found.
False: Early stopping will be disabled.None: The default callback monitoring'val_loss'is created.Default:
None.
from pytorch_lightning.callbacks import EarlyStopping
# default used by the Trainer
early_stop = EarlyStopping(
monitor='val_loss',
patience=3,
strict=False,
verbose=False,
mode='min'
)
trainer = Trainer(early_stop_callback=early_stop)
Note
If 'val_loss' is not found will work as if early stopping is disabled.
fast_dev_run¶
Runs 1 batch of train, test and val to find any bugs (ie: a sort of unit test).
Under the hood the pseudocode looks like this:
# loading
__init__()
prepare_data
# test training step
training_batch = next(train_dataloader)
training_step(training_batch)
# test val step
val_batch = next(val_dataloader)
out = validation_step(val_batch)
validation_epoch_end([out])
# default used by the Trainer
trainer = Trainer(fast_dev_run=False)
# runs 1 train, val, test batch and program ends
trainer = Trainer(fast_dev_run=True)
gpus¶
Number of GPUs to train on
or Which GPUs to train on
can handle strings
# default used by the Trainer (ie: train on CPU)
trainer = Trainer(gpus=None)
Example:
# int: train on 2 gpus
trainer = Trainer(gpus=2)
# list: train on GPUs 1, 4 (by bus ordering)
trainer = Trainer(gpus=[1, 4])
trainer = Trainer(gpus='1, 4') # equivalent
# -1: train on all gpus
trainer = Trainer(gpus=-1)
trainer = Trainer(gpus='-1') # equivalent
# combine with num_nodes to train on multiple GPUs across nodes
# uses 8 gpus in total
trainer = Trainer(gpus=2, num_nodes=4)
See also
gradient_clip_val¶
Gradient clipping value
0 means don’t clip.
# default used by the Trainer
trainer = Trainer(gradient_clip_val=0.0)
limit_test_batches¶
How much of test dataset to check.
# default used by the Trainer
trainer = Trainer(limit_test_batches=1.0)
# run through only 25% of the test set each epoch
trainer = Trainer(limit_test_batches=0.25)
# run for only 10 batches
trainer = Trainer(limit_test_batches=10)
In the case of multiple test dataloaders, the limit applies to each dataloader individually.
limit_val_batches¶
How much of validation dataset to check. Useful when debugging or testing something that happens at the end of an epoch.
# default used by the Trainer
trainer = Trainer(limit_val_batches=1.0)
# run through only 25% of the validation set each epoch
trainer = Trainer(limit_val_batches=0.25)
# run for only 10 batches
trainer = Trainer(limit_val_batches=10)
In the case of multiple validation dataloaders, the limit applies to each dataloader individually.
log_gpu_memory¶
Options:
None
‘min_max’
‘all’
# default used by the Trainer
trainer = Trainer(log_gpu_memory=None)
# log all the GPUs (on master node only)
trainer = Trainer(log_gpu_memory='all')
# log only the min and max memory on the master node
trainer = Trainer(log_gpu_memory='min_max')
Note
Might slow performance because it uses the output of nvidia-smi.
log_save_interval¶
Writes logs to disk this often.
# default used by the Trainer
trainer = Trainer(log_save_interval=100)
logger¶
Logger (or iterable collection of loggers) for experiment tracking.
from pytorch_lightning.loggers import TensorBoardLogger
# default logger used by trainer
logger = TensorBoardLogger(
save_dir=os.getcwd(),
version=1,
name='lightning_logs'
)
Trainer(logger=logger)
max_epochs¶
Stop training once this number of epochs is reached
# default used by the Trainer
trainer = Trainer(max_epochs=1000)
min_epochs¶
Force training for at least these many epochs
# default used by the Trainer
trainer = Trainer(min_epochs=1)
max_steps¶
Stop training after this number of steps Training will stop if max_steps or max_epochs have reached (earliest).
# Default (disabled)
trainer = Trainer(max_steps=None)
# Stop after 100 steps
trainer = Trainer(max_steps=100)
min_steps¶
Force training for at least these number of steps. Trainer will train model for at least min_steps or min_epochs (latest).
# Default (disabled)
trainer = Trainer(min_steps=None)
# Run at least for 100 steps (disable min_epochs)
trainer = Trainer(min_steps=100, min_epochs=0)
num_nodes¶
Number of GPU nodes for distributed training.
# default used by the Trainer
trainer = Trainer(num_nodes=1)
# to train on 8 nodes
trainer = Trainer(num_nodes=8)
num_processes¶
Number of processes to train with. Automatically set to the number of GPUs
when using distrbuted_backend="ddp". Set to a number greater than 1 when
using distributed_backend="ddp_cpu" to mimic distributed training on a
machine without GPUs. This is useful for debugging, but will not provide
any speedup, since single-process Torch already makes effient use of multiple
CPUs.
# Simulate DDP for debugging on your GPU-less laptop
trainer = Trainer(distributed_backend="ddp_cpu", num_processes=2)
num_sanity_val_steps¶
Sanity check runs n batches of val before starting the training routine. This catches any bugs in your validation without having to wait for the first validation check. The Trainer uses 5 steps by default. Turn it off or modify it here.
# default used by the Trainer
trainer = Trainer(num_sanity_val_steps=5)
# turn it off
trainer = Trainer(num_sanity_val_steps=0)
num_tpu_cores¶
Warning
Deprecated since version 0.7.6.
Use tpu_cores instead. Will remove 0.9.0.
Example:
python -m torch_xla.distributed.xla_dist
--tpu=$TPU_POD_NAME
--conda-env=torch-xla-nightly
--env=XLA_USE_BF16=1
-- python your_trainer_file.py
prepare_data_per_node¶
If True will call prepare_data() on LOCAL_RANK=0 for every node. If False will only call from NODE_RANK=0, LOCAL_RANK=0
# default
Trainer(prepare_data_per_node=True)
# use only NODE_RANK=0, LOCAL_RANK=0
Trainer(prepare_data_per_node=False)
tpu_cores¶
How many TPU cores to train on (1 or 8).
Which TPU core to train on [1-8]
A single TPU v2 or v3 has 8 cores. A TPU pod has up to 2048 cores. A slice of a POD means you get as many cores as you request.
Your effective batch size is batch_size * total tpu cores.
Note
No need to add a DistributedDataSampler, Lightning automatically does it for you.
This parameter can be either 1 or 8.
# your_trainer_file.py
# default used by the Trainer (ie: train on CPU)
trainer = Trainer(tpu_cores=None)
# int: train on a single core
trainer = Trainer(tpu_cores=1)
# list: train on a single selected core
trainer = Trainer(tpu_cores=[2])
# int: train on all cores few cores
trainer = Trainer(tpu_cores=8)
# for 8+ cores must submit via xla script with
# a max of 8 cores specified. The XLA script
# will duplicate script onto each TPU in the POD
trainer = Trainer(tpu_cores=8)
To train on more than 8 cores (ie: a POD), submit this script using the xla_dist script.
Example:
python -m torch_xla.distributed.xla_dist
--tpu=$TPU_POD_NAME
--conda-env=torch-xla-nightly
--env=XLA_USE_BF16=1
-- python your_trainer_file.py
overfit_pct¶
Warning
Deprecated since version 0.8.0..
Use overfit_batches. Will be removed in 0.10.0.
overfit_batches¶
Uses this much data of the training set. If nonzero, will use the same training set for validation and testing. If the training dataloaders have shuffle=True, Lightning will automatically disable it.
Useful for quickly debugging or trying to overfit on purpose.
# default used by the Trainer
trainer = Trainer(overfit_batches=0.0)
# use only 1% of the train set (and use the train set for val and test)
trainer = Trainer(overfit_batches=0.01)
# overfit on 10 of the same batches
trainer = Trainer(overfit_batches=10)
precision¶
Full precision (32), half precision (16). Can be used on CPU, GPU or TPUs.
If used on TPU will use torch.bfloat16 but tensor printing will still show torch.float32.
# default used by the Trainer
trainer = Trainer(precision=32)
# 16-bit precision
trainer = Trainer(precision=16)
Example:
# one day
trainer = Trainer(precision=8|4|2)
print_nan_grads¶
Warning
Deprecated since version 0.7.2..
Has no effect. When detected, NaN grads will be printed automatically. Will remove 0.9.0.
process_position¶
Orders the progress bar. Useful when running multiple trainers on the same node.
# default used by the Trainer
trainer = Trainer(process_position=0)
Note
This argument is ignored if a custom callback is passed to callbacks.
profiler¶
To profile individual steps during training and assist in identifying bottlenecks.
See the profiler documentation. for more details.
from pytorch_lightning.profiler import SimpleProfiler, AdvancedProfiler
# default used by the Trainer
trainer = Trainer(profiler=None)
# to profile standard training events
trainer = Trainer(profiler=True)
# equivalent to profiler=True
trainer = Trainer(profiler=SimpleProfiler())
# advanced profiler for function-level stats
trainer = Trainer(profiler=AdvancedProfiler())
progress_bar_refresh_rate¶
How often to refresh progress bar (in steps). In notebooks, faster refresh rates (lower number) is known to crash them because of their screen refresh rates, so raise it to 50 or more.
# default used by the Trainer
trainer = Trainer(progress_bar_refresh_rate=1)
# disable progress bar
trainer = Trainer(progress_bar_refresh_rate=0)
Note
This argument is ignored if a custom callback is passed to callbacks.
reload_dataloaders_every_epoch¶
Set to True to reload dataloaders every epoch.
# if False (default)
train_loader = model.train_dataloader()
for epoch in epochs:
for batch in train_loader:
...
# if True
for epoch in epochs:
train_loader = model.train_dataloader()
for batch in train_loader:
replace_sampler_ddp¶
Enables auto adding of distributed sampler.
# default used by the Trainer
trainer = Trainer(replace_sampler_ddp=True)
By setting to False, you have to add your own distributed sampler:
# default used by the Trainer
sampler = torch.utils.data.distributed.DistributedSampler(dataset, shuffle=True)
dataloader = DataLoader(dataset, batch_size=32, sampler=sampler)
resume_from_checkpoint¶
To resume training from a specific checkpoint pass in the path here.
# default used by the Trainer
trainer = Trainer(resume_from_checkpoint=None)
# resume from a specific checkpoint
trainer = Trainer(resume_from_checkpoint='some/path/to/my_checkpoint.ckpt')
row_log_interval¶
How often to add logging rows (does not write to disk)
# default used by the Trainer
trainer = Trainer(row_log_interval=50)
use_amp:
Warning
Deprecated since version 0.7.0.
Use precision instead. Will remove 0.9.0.
show_progress_bar¶
Warning
Deprecated since version 0.7.2.
Set progress_bar_refresh_rate to 0 instead. Will remove 0.9.0.
val_percent_check¶
Warning
deprecated in v0.8.0 please use limit_val_batches. Will remove in 0.10.0
test_percent_check¶
Warning
deprecated in v0.8.0 please use limit_test_batches. Will remove in 0.10.0
train_percent_check¶
Warning
deprecated in v0.8.0 please use limit_train_batches. Will remove in 0.10.0
track_grad_norm¶
no tracking (-1)
Otherwise tracks that norm (2 for 2-norm)
# default used by the Trainer
trainer = Trainer(track_grad_norm=-1)
# track the 2-norm
trainer = Trainer(track_grad_norm=2)
limit_train_batches¶
How much of training dataset to check. Useful when debugging or testing something that happens at the end of an epoch.
# default used by the Trainer
trainer = Trainer(limit_train_batches=1.0)
Example:
# default used by the Trainer
trainer = Trainer(limit_train_batches=1.0)
# run through only 25% of the training set each epoch
trainer = Trainer(limit_train_batches=0.25)
# run through only 10 batches of the training set each epoch
trainer = Trainer(limit_train_batches=10)
truncated_bptt_steps¶
Truncated back prop breaks performs backprop every k steps of a much longer sequence.
If this is enabled, your batches will automatically get truncated and the trainer will apply Truncated Backprop to it.
# default used by the Trainer (ie: disabled)
trainer = Trainer(truncated_bptt_steps=None)
# backprop every 5 steps in a batch
trainer = Trainer(truncated_bptt_steps=5)
Note
Make sure your batches have a sequence dimension.
Lightning takes care to split your batch along the time-dimension.
# we use the second as the time dimension
# (batch, time, ...)
sub_batch = batch[0, 0:t, ...]
Using this feature requires updating your LightningModule’s
pytorch_lightning.core.LightningModule.training_step() to include a hiddens arg
with the hidden
# Truncated back-propagation through time
def training_step(self, batch, batch_idx, hiddens):
# hiddens are the hiddens from the previous truncated backprop step
out, hiddens = self.lstm(data, hiddens)
return {
"loss": ...,
"hiddens": hiddens # remember to detach() this
}
To modify how the batch is split,
override pytorch_lightning.core.LightningModule.tbptt_split_batch():
class LitMNIST(LightningModule):
def tbptt_split_batch(self, batch, split_size):
# do your own splitting on the batch
return splits
val_check_interval¶
How often within one training epoch to check the validation set. Can specify as float or int.
use (float) to check within a training epoch
use (int) to check every n steps (batches)
# default used by the Trainer
trainer = Trainer(val_check_interval=1.0)
# check validation set 4 times during a training epoch
trainer = Trainer(val_check_interval=0.25)
# check validation set every 1000 training batches
# use this when using iterableDataset and your dataset has no length
# (ie: production cases with streaming data)
trainer = Trainer(val_check_interval=1000)
weights_save_path¶
Directory of where to save weights if specified.
# default used by the Trainer
trainer = Trainer(weights_save_path=os.getcwd())
# save to your custom path
trainer = Trainer(weights_save_path='my/path')
Example:
# if checkpoint callback used, then overrides the weights path
# **NOTE: this saves weights to some/path NOT my/path
checkpoint = ModelCheckpoint(filepath='some/path')
trainer = Trainer(
checkpoint_callback=checkpoint,
weights_save_path='my/path'
)
weights_summary¶
Prints a summary of the weights when training begins. Options: ‘full’, ‘top’, None.
# default used by the Trainer (ie: print summary of top level modules)
trainer = Trainer(weights_summary='top')
# print full summary of all modules and submodules
trainer = Trainer(weights_summary='full')
# don't print a summary
trainer = Trainer(weights_summary=None)
Trainer class¶
-
class
pytorch_lightning.trainer.Trainer(logger=True, checkpoint_callback=True, early_stop_callback=False, callbacks=None, default_root_dir=None, gradient_clip_val=0, process_position=0, num_nodes=1, num_processes=1, gpus=None, auto_select_gpus=False, tpu_cores=None, log_gpu_memory=None, progress_bar_refresh_rate=1, overfit_batches=0.0, track_grad_norm=-1, check_val_every_n_epoch=1, fast_dev_run=False, accumulate_grad_batches=1, max_epochs=1000, min_epochs=1, max_steps=None, min_steps=None, limit_train_batches=1.0, limit_val_batches=1.0, limit_test_batches=1.0, val_check_interval=1.0, log_save_interval=100, row_log_interval=50, distributed_backend=None, precision=32, print_nan_grads=False, weights_summary='top', weights_save_path=None, num_sanity_val_steps=2, truncated_bptt_steps=None, resume_from_checkpoint=None, profiler=None, benchmark=False, deterministic=False, reload_dataloaders_every_epoch=False, auto_lr_find=False, replace_sampler_ddp=True, terminate_on_nan=False, auto_scale_batch_size=False, prepare_data_per_node=True, amp_level='O2', num_tpu_cores=None, use_amp=None, show_progress_bar=None, val_percent_check=None, test_percent_check=None, train_percent_check=None, overfit_pct=None)[source] Bases:
pytorch_lightning.trainer.training_io.TrainerIOMixin,pytorch_lightning.trainer.callback_hook.TrainerCallbackHookMixin,pytorch_lightning.trainer.model_hooks.TrainerModelHooksMixin,pytorch_lightning.trainer.optimizers.TrainerOptimizersMixin,pytorch_lightning.trainer.auto_mix_precision.TrainerAMPMixin,pytorch_lightning.trainer.distrib_parts.TrainerDPMixin,pytorch_lightning.trainer.distrib_data_parallel.TrainerDDPMixin,pytorch_lightning.trainer.logging.TrainerLoggingMixin,pytorch_lightning.trainer.training_tricks.TrainerTrainingTricksMixin,pytorch_lightning.trainer.data_loading.TrainerDataLoadingMixin,pytorch_lightning.trainer.evaluation_loop.TrainerEvaluationLoopMixin,pytorch_lightning.trainer.training_loop.TrainerTrainLoopMixin,pytorch_lightning.trainer.callback_config.TrainerCallbackConfigMixin,pytorch_lightning.trainer.lr_finder.TrainerLRFinderMixin,pytorch_lightning.trainer.deprecated_api.TrainerDeprecatedAPITillVer0_9,pytorch_lightning.trainer.deprecated_api.TrainerDeprecatedAPITillVer0_10Example
>>> import torch >>> from torch.nn import functional as F >>> from torch.utils.data import Dataset, DataLoader
>>> # Define model >>> class SimpleModel(LightningModule): ... def __init__(self): ... super().__init__() ... self.l1 = torch.nn.Linear(in_features=64, out_features=4) ... ... def forward(self, x): ... return torch.relu(self.l1(x.view(x.size(0), -1))) ... ... def training_step(self, batch, batch_nb): ... x, y = batch ... loss = F.cross_entropy(self(x), y) ... return {'loss': loss, 'log': {'train_loss': loss}} ... ... def test_step(self, batch, batch_nb): ... x, y = batch ... loss = F.cross_entropy(self(x), y) ... return {'loss': loss, 'log': {'train_loss': loss}} ... ... def configure_optimizers(self): ... return torch.optim.Adam(self.parameters(), lr=0.02) ... >>> # Define dataset >>> class SimpleDataset(Dataset): ... def __init__(self, num_samples=200): ... self.input_seq = torch.randn(num_samples, 64) ... self.output_seq = torch.randint(0, 4, (num_samples,)) ... ... def __len__(self): ... return len(self.input_seq) ... ... def __getitem__(self, item): ... return self.input_seq[item], self.output_seq[item] ... >>> train_loader = DataLoader(SimpleDataset(), batch_size=8) >>> model = SimpleModel() >>> # Define Trainer and fit model >>> trainer = Trainer(max_epochs=1, progress_bar_refresh_rate=0) >>> trainer.fit(model, train_loader) 1 >>> trainer.test(model, train_loader) 1
Customize every aspect of training via flags
- Parameters
logger¶ (
Union[LightningLoggerBase,Iterable[LightningLoggerBase],bool]) – Logger (or iterable collection of loggers) for experiment tracking.checkpoint_callback¶ (
Union[ModelCheckpoint,bool]) – Callback for checkpointing.early_stop_callback¶ (
pytorch_lightning.callbacks.EarlyStopping) –callbacks¶ (
Optional[List[Callback]]) – Add a list of callbacks.default_root_dir¶ (
Optional[str]) – Default path for logs and weights when no logger/ckpt_callback passedgradient_clip¶ –
Warning
Deprecated since version 0.7.0.
Use gradient_clip_val instead. Will remove 0.9.0.
process_position¶ (
int) – orders the progress bar when running multiple models on same machine.num_nodes¶ (
int) – number of GPU nodes for distributed training.nb_gpu_nodes¶ –
Warning
Deprecated since version 0.7.0.
Use num_nodes instead. Will remove 0.9.0.
gpus¶ (
Union[int,str,List[int],None]) – Which GPUs to train on.auto_select_gpus¶ (
bool) – If enabled and gpus is an integer, pick available gpus automatically. This is especially useful when GPUs are configured to be in “exclusive mode”, such that only one process at a time can access them.tpu_cores¶ (
Union[int,str,List[int],None]) – How many TPU cores to train on (1 or 8) / Single TPU to train on [1]num_tpu_cores¶ (
Optional[int]) – How many TPU cores to train on (1 or 8) .. warning:: .. deprecated:: 0.7.6. Will remove 0.9.0.log_gpu_memory¶ (
Optional[str]) – None, ‘min_max’, ‘all’. Might slow performanceshow_progress_bar¶ –
Warning
Deprecated since version 0.7.2.
Set progress_bar_refresh_rate to positive integer to enable. Will remove 0.9.0.
progress_bar_refresh_rate¶ (
int) – How often to refresh progress bar (in steps). Value0disables progress bar. Ignored when a custom callback is passed tocallbacks.overfit_batches¶ (
Union[int,float]) – Overfit a percent of training data (float) or a set number of batches (int). Default: 0.0overfit_pct¶ (
Optional[float]) –Warning
Deprecated since version 0.8.0.
Use overfit_batches instead. Will be removed in 0.10.0.
track_grad_norm¶ (
Union[int,float,str]) – -1 no tracking. Otherwise tracks that p-norm. May be set to ‘inf’ infinity-norm.check_val_every_n_epoch¶ (
int) – Check val every n train epochs.fast_dev_run¶ (
bool) – runs 1 batch of train, test and val to find any bugs (ie: a sort of unit test).accumulate_grad_batches¶ (
Union[int,Dict[int,int],List[list]]) – Accumulates grads every k batches or as set up in the dict.max_epochs¶ (
int) – Stop training once this number of epochs is reached.max_nb_epochs¶ –
Warning
Deprecated since version 0.7.0.
Use max_epochs instead. Will remove 0.9.0.
min_epochs¶ (
int) – Force training for at least these many epochsmin_nb_epochs¶ –
Warning
Deprecated since version 0.7.0.
Use min_epochs instead. Will remove 0.9.0.
max_steps¶ (
Optional[int]) – Stop training after this number of steps. Disabled by default (None).min_steps¶ (
Optional[int]) – Force training for at least these number of steps. Disabled by default (None).limit_train_batches¶ (
Union[int,float]) – How much of training dataset to check (floats = percent, int = num_batches)limit_val_batches¶ (
Union[int,float]) – How much of validation dataset to check (floats = percent, int = num_batches)limit_test_batches¶ (
Union[int,float]) – How much of test dataset to check (floats = percent, int = num_batches)train_percent_check¶ (
Optional[float]) –Warning
Deprecated since version 0.8.0.
Use limit_train_batches instead. Will remove v0.10.0.
val_percent_check¶ (
Optional[float]) –Warning
Deprecated since version 0.8.0.
Use limit_val_batches instead. Will remove v0.10.0.
test_percent_check¶ (
Optional[float]) –Warning
Deprecated since version 0.8.0.
Use limit_test_batches instead. Will remove v0.10.0.
val_check_interval¶ (
Union[int,float]) – How often within one training epoch to check the validation setrow_log_interval¶ (
int) – How often to add logging rows (does not write to disk)add_row_log_interval¶ –
Warning
Deprecated since version 0.7.0.
Use row_log_interval instead. Will remove 0.9.0.
distributed_backend¶ (
Optional[str]) – The distributed backend to use (dp, ddp, ddp2, ddp_spawn, ddp_cpu)use_amp¶ –
Warning
Deprecated since version 0.7.0.
Use precision instead. Will remove 0.9.0.
precision¶ (
int) – Full precision (32), half precision (16).Warning
Deprecated since version 0.7.2.
Has no effect. When detected, NaN grads will be printed automatically. Will remove 0.9.0.
weights_summary¶ (
Optional[str]) – Prints a summary of the weights when training begins.weights_save_path¶ (
Optional[str]) – Where to save weights if specified. Will override default_root_dir for checkpoints only. Use this if for whatever reason you need the checkpoints stored in a different place than the logs written in default_root_dir.amp_level¶ (
str) – The optimization level to use (O1, O2, etc…).num_sanity_val_steps¶ (
int) – Sanity check runs n batches of val before starting the training routine.truncated_bptt_steps¶ (
Optional[int]) – Truncated back prop breaks performs backprop every k steps ofresume_from_checkpoint¶ (
Optional[str]) – To resume training from a specific checkpoint pass in the path here. This can be a URL.profiler¶ (
Union[BaseProfiler,bool,None]) – To profile individual steps during training and assist inreload_dataloaders_every_epoch¶ (
bool) – Set to True to reload dataloaders every epochauto_lr_find¶ (
Union[bool,str]) – If set to True, will initially run a learning rate finder, trying to optimize initial learning for faster convergence. Sets learning rate in self.lr or self.learning_rate in the LightningModule. To use a different key, set a string instead of True with the key name.replace_sampler_ddp¶ (
bool) – Explicitly enables or disables sampler replacement. If not specified this will toggled automatically ddp is usedterminate_on_nan¶ (
bool) – If set to True, will terminate training (by raising a ValueError) at the end of each training batch, if any of the parameters or the loss are NaN or +/-inf.auto_scale_batch_size¶ (
Union[str,bool]) – If set to True, will initially run a batch size finder trying to find the largest batch size that fits into memory. The result will be stored in self.batch_size in the LightningModule. Additionally, can be set to either power that estimates the batch size through a power search or binsearch that estimates the batch size through a binary search.prepare_data_per_node¶ (
bool) – If True, each LOCAL_RANK=0 will call prepare data. Otherwise only NODE_RANK=0, LOCAL_RANK=0 will prepare data
-
classmethod
add_argparse_args(parent_parser)[source] Extends existing argparse by default Trainer attributes.
- Parameters
parent_parser¶ (
ArgumentParser) – The custom cli arguments parser, which will be extended by the Trainer default arguments.
Only arguments of the allowed types (str, float, int, bool) will extend the parent_parser.
Examples
>>> import argparse >>> import pprint >>> parser = argparse.ArgumentParser() >>> parser = Trainer.add_argparse_args(parser) >>> args = parser.parse_args([]) >>> pprint.pprint(vars(args)) {... 'check_val_every_n_epoch': 1, 'checkpoint_callback': True, 'default_root_dir': None, 'deterministic': False, 'distributed_backend': None, 'early_stop_callback': False, ... 'logger': True, 'max_epochs': 1000, 'max_steps': None, 'min_epochs': 1, 'min_steps': None, ... 'profiler': None, 'progress_bar_refresh_rate': 1, ...}
- Return type
-
check_model_configuration(model)[source] Checks that the model is configured correctly before training or testing is started.
- Parameters
model¶ (
LightningModule) – The model to check the configuration.
-
fit(model, train_dataloader=None, val_dataloaders=None)[source] Runs the full optimization routine.
- Parameters
model¶ (
LightningModule) – Model to fit.train_dataloader¶ (
Optional[DataLoader]) – A Pytorch DataLoader with training samples. If the model has a predefined train_dataloader method this will be skipped.val_dataloaders¶ (
Union[DataLoader,List[DataLoader],None]) – Either a single Pytorch Dataloader or a list of them, specifying validation samples. If the model has a predefined val_dataloaders method this will be skipped
Example:
# Option 1, # Define the train_dataloader() and val_dataloader() fxs # in the lightningModule # RECOMMENDED FOR MOST RESEARCH AND APPLICATIONS TO MAINTAIN READABILITY trainer = Trainer() model = LightningModule() trainer.fit(model) # Option 2 # in production cases we might want to pass different datasets to the same model # Recommended for PRODUCTION SYSTEMS train, val = DataLoader(...), DataLoader(...) trainer = Trainer() model = LightningModule() trainer.fit(model, train_dataloader=train, val_dataloaders=val) # Option 1 & 2 can be mixed, for example the training set can be # defined as part of the model, and validation can then be feed to .fit()
-
classmethod
from_argparse_args(args, **kwargs)[source] Create an instance from CLI arguments.
- Parameters
Example
>>> parser = ArgumentParser(add_help=False) >>> parser = Trainer.add_argparse_args(parser) >>> parser.add_argument('--my_custom_arg', default='something') >>> args = Trainer.parse_argparser(parser.parse_args("")) >>> trainer = Trainer.from_argparse_args(args, logger=False)
- Return type
-
classmethod
get_deprecated_arg_names()[source] Returns a list with deprecated Trainer arguments.
- Return type
-
classmethod
get_init_arguments_and_types()[source] Scans the Trainer signature and returns argument names, types and default values.
- Returns
(argument name, set with argument types, argument default value).
- Return type
List with tuples of 3 values
Examples
>>> args = Trainer.get_init_arguments_and_types() >>> import pprint >>> pprint.pprint(sorted(args)) [('accumulate_grad_batches', (<class 'int'>, typing.Dict[int, int], typing.List[list]), 1), ... ('callbacks', (typing.List[pytorch_lightning.callbacks.base.Callback], <class 'NoneType'>), None), ('check_val_every_n_epoch', (<class 'int'>,), 1), ... ('max_epochs', (<class 'int'>,), 1000), ... ('precision', (<class 'int'>,), 32), ('prepare_data_per_node', (<class 'bool'>,), True), ('print_nan_grads', (<class 'bool'>,), False), ('process_position', (<class 'int'>,), 0), ('profiler', (<class 'pytorch_lightning.profiler.profilers.BaseProfiler'>, <class 'bool'>, <class 'NoneType'>), None), ...
-
classmethod
parse_argparser(arg_parser)[source] Parse CLI arguments, required for custom bool types.
- Return type
-
run_pretrain_routine(model)[source] Sanity check a few things before starting actual training.
- Parameters
model¶ (
LightningModule) – The model to run sanity test on.
-
test(model=None, test_dataloaders=None, ckpt_path='best')[source] Separates from fit to make sure you never run on your test set until you want to.
- Parameters
model¶ (
Optional[LightningModule]) – The model to test.test_dataloaders¶ (
Union[DataLoader,List[DataLoader],None]) – Either a single Pytorch Dataloader or a list of them, specifying validation samples.ckpt_path¶ (
Optional[str]) – Eitherbestor path to the checkpoint you wish to test. IfNone, use the weights from the last epoch to test. Default tobest.
Example:
# Option 1 # run test with the best checkpoint from ``ModelCheckpoint`` after fitting. test = DataLoader(...) trainer = Trainer() model = LightningModule() trainer.fit(model) trainer.test(test_dataloaders=test) # Option 2 # run test with the specified checkpoint after fitting test = DataLoader(...) trainer = Trainer() model = LightningModule() trainer.fit(model) trainer.test(test_dataloaders=test, ckpt_path='path/to/checkpoint.ckpt') # Option 3 # run test with the weights from the end of training after fitting test = DataLoader(...) trainer = Trainer() model = LightningModule() trainer.fit(model) trainer.test(test_dataloaders=test, ckpt_path=None) # Option 4 # run test from a loaded model. ``ckpt_path`` is ignored in this case. test = DataLoader(...) model = LightningModule.load_from_checkpoint('path/to/checkpoint.ckpt') trainer = Trainer() trainer.test(model, test_dataloaders=test)
-
property
is_global_zero[source] this is just empty shell for code implemented in other class.
-
property
num_gpus[source] this is just empty shell for code implemented in other class.
