ModelPruning¶
- class pytorch_lightning.callbacks.ModelPruning(pruning_fn, parameters_to_prune=(), parameter_names=None, use_global_unstructured=True, amount=0.5, apply_pruning=True, make_pruning_permanent=True, use_lottery_ticket_hypothesis=True, resample_parameters=False, pruning_dim=None, pruning_norm=None, verbose=0, prune_on_train_epoch_end=True)[source]¶
Bases:
pytorch_lightning.callbacks.callback.CallbackModel pruning Callback, using PyTorch’s prune utilities. This callback is responsible of pruning networks parameters during training.
To learn more about pruning with PyTorch, please take a look at this tutorial.
Warning
ModelPruningis in beta and subject to change.parameters_to_prune = [(model.mlp_1, "weight"), (model.mlp_2, "weight")] trainer = Trainer( callbacks=[ ModelPruning( pruning_fn="l1_unstructured", parameters_to_prune=parameters_to_prune, amount=0.01, use_global_unstructured=True, ) ] )
When
parameters_to_pruneisNone,parameters_to_prunewill contain all parameters from the model. The user can overridefilter_parameters_to_pruneto filter anynn.Moduleto be pruned.- Parameters
pruning_fn¶ (
Union[Callable,str]) – Function from torch.nn.utils.prune module or your own PyTorchBasePruningMethodsubclass. Can also be string e.g. “l1_unstructured”. See pytorch docs for more details.parameters_to_prune¶ (
Sequence[Tuple[Module,str]]) – List of tuples(nn.Module, "parameter_name_string").parameter_names¶ (
Optional[List[str]]) – List of parameter names to be pruned from the nn.Module. Can either be"weight"or"bias".use_global_unstructured¶ (
bool) – Whether to apply pruning globally on the model. Ifparameters_to_pruneis provided, global unstructured will be restricted on them.amount¶ (
Union[int,float,Callable[[int],Union[int,float]]]) –Quantity of parameters to prune:
float. Between 0.0 and 1.0. Represents the fraction of parameters to prune.int. Represents the absolute number of parameters to prune.Callable. For dynamic values. Will be called every epoch. Should return a value.
apply_pruning¶ (
Union[bool,Callable[[int],bool]]) –Whether to apply pruning.
bool. Always apply it or not.Callable[[epoch], bool]. For dynamic values. Will be called every epoch.
make_pruning_permanent¶ (
bool) – Whether to remove all reparametrization pre-hooks and apply masks when training ends or the model is saved.use_lottery_ticket_hypothesis¶ (
Union[bool,Callable[[int],bool]]) –See The lottery ticket hypothesis:
bool. Whether to apply it or not.Callable[[epoch], bool]. For dynamic values. Will be called every epoch.
resample_parameters¶ (
bool) – Used withuse_lottery_ticket_hypothesis. If True, the model parameters will be resampled, otherwise, the exact original parameters will be used.pruning_dim¶ (
Optional[int]) – If you are using a structured pruning method you need to specify the dimension.pruning_norm¶ (
Optional[int]) – If you are usingln_structuredyou need to specify the norm.verbose¶ (
int) – Verbosity level. 0 to disable, 1 to log overall sparsity, 2 to log per-layer sparsityprune_on_train_epoch_end¶ (
bool) – whether to apply pruning at the end of the training epoch. If this isFalse, then the check runs at the end of the validation epoch.
- Raises
MisconfigurationException – If
parameter_namesis neither"weight"nor"bias", if the providedpruning_fnis not supported, ifpruning_dimis not provided when"unstructured", ifpruning_normis not provided when"ln_structured", ifpruning_fnis neitherstrnortorch.nn.utils.prune.BasePruningMethod, or ifamountis none ofint,floatandCallable.
- apply_lottery_ticket_hypothesis()[source]¶
Lottery ticket hypothesis algorithm (see page 2 of the paper):
Randomly initialize a neural network
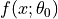 (where
(where 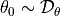 ).
).Train the network for
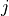 iterations, arriving at parameters
iterations, arriving at parameters 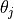 .
.Prune
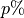 of the parameters in , creating a mask
of the parameters in , creating a mask 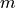 .
.Reset the remaining parameters to their values in
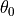 , creating the winning ticket
, creating the winning ticket 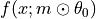 .
.
This function implements the step 4.
The
resample_parametersargument can be used to reset the parameters with a new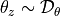
- Return type
- filter_parameters_to_prune(parameters_to_prune=())[source]¶
This function can be overridden to control which module to prune.
- make_pruning_permanent(module)[source]¶
Removes pruning buffers from any pruned modules.
Adapted from https://github.com/pytorch/pytorch/blob/1.7.1/torch/nn/utils/prune.py#L1176-L1180
- Return type
- on_save_checkpoint(trainer, pl_module, checkpoint)[source]¶
Called when saving a checkpoint to give you a chance to store anything else you might want to save.
- Parameters
pl_module¶ (
LightningModule) – the currentLightningModuleinstance.checkpoint¶ (
Dict[str,Any]) – the checkpoint dictionary that will be saved.
- Return type
- Returns
None or the callback state. Support for returning callback state will be removed in v1.8.
Deprecated since version v1.6: Returning a value from this method was deprecated in v1.6 and will be removed in v1.8. Implement
Callback.state_dictinstead to return state. In v1.8Callback.on_save_checkpointcan only return None.
- on_train_epoch_end(trainer, pl_module)[source]¶
Called when the train epoch ends.
To access all batch outputs at the end of the epoch, either:
Implement training_epoch_end in the LightningModule and access outputs via the module OR
Cache data across train batch hooks inside the callback implementation to post-process in this hook.
- Return type
