Accelerator¶
The Accelerator connects a Lightning Trainer to arbitrary hardware (CPUs, GPUs, TPUs, IPUs, MPS, …). Currently there are accelerators for:
The Accelerator is part of the Strategy which manages communication across multiple devices (distributed communication). Whenever the Trainer, the loops or any other component in Lightning needs to talk to hardware, it calls into the Strategy and the Strategy calls into the Accelerator.
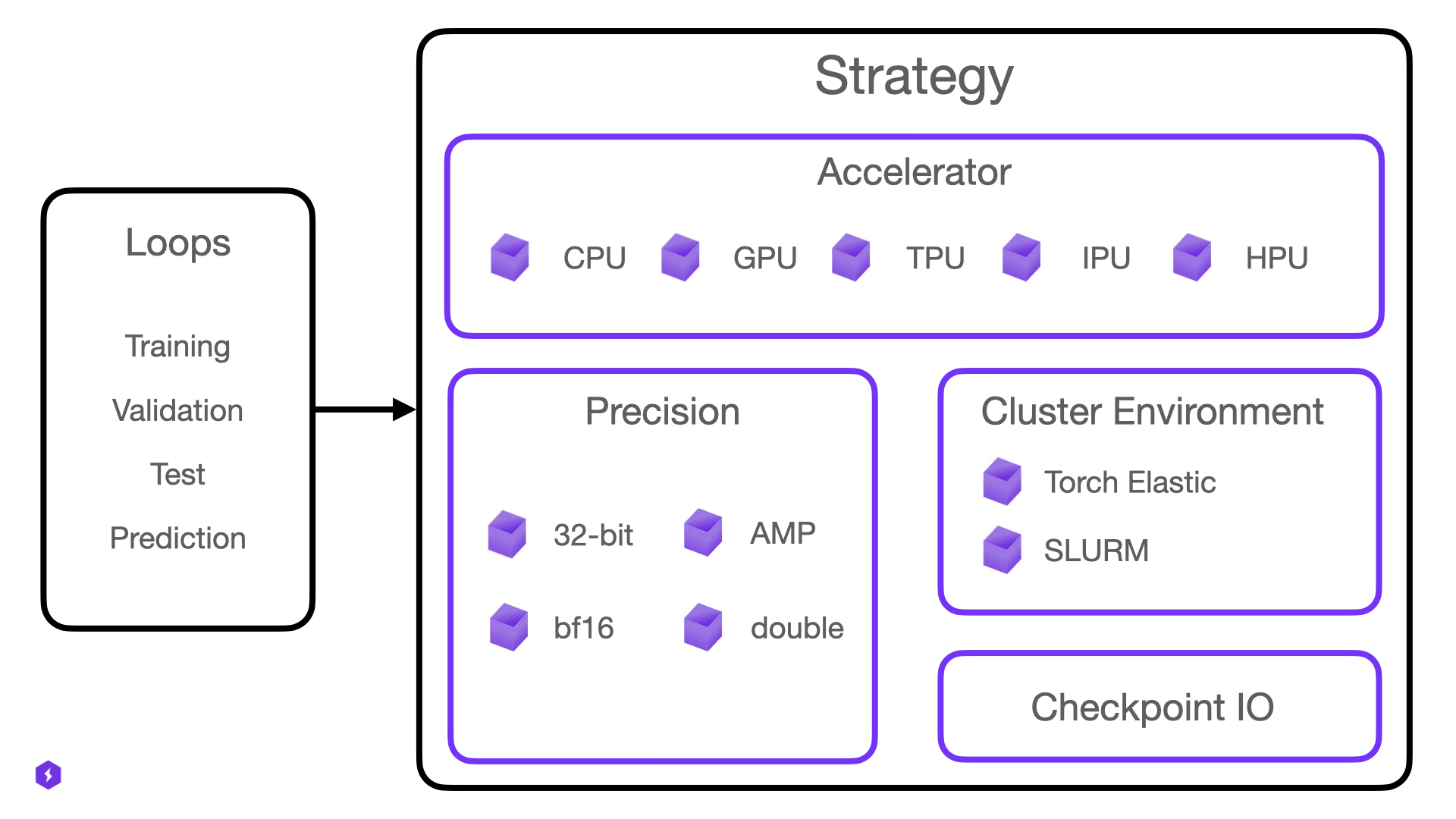
We expose Accelerators and Strategies mainly for expert users who want to extend Lightning to work with new hardware and distributed training or clusters.
Create a Custom Accelerator¶
Warning
This is an experimental feature.
Here is how you create a new Accelerator.
Let’s pretend we want to integrate the fictional XPU accelerator and we have access to its hardware through a library
xpulib.
import xpulib
class XPUAccelerator(Accelerator):
"""Support for a hypothetical XPU, optimized for large-scale machine learning."""
@staticmethod
def parse_devices(devices: Any) -> Any:
# Put parsing logic here how devices can be passed into the Trainer
# via the `devices` argument
return devices
@staticmethod
def get_parallel_devices(devices: Any) -> Any:
# Here, convert the device indices to actual device objects
return [torch.device("xpu", idx) for idx in devices]
@staticmethod
def auto_device_count() -> int:
# Return a value for auto-device selection when `Trainer(devices="auto")`
return xpulib.available_devices()
@staticmethod
def is_available() -> bool:
return xpulib.is_available()
def get_device_stats(self, device: Union[str, torch.device]) -> Dict[str, Any]:
# Return optional device statistics for loggers
return {}
Finally, add the XPUAccelerator to the Trainer:
from lightning.pytorch import Trainer
accelerator = XPUAccelerator()
trainer = Trainer(accelerator=accelerator, devices=2)
Learn more about Strategies and how they interact with the Accelerator.
Registering Accelerators¶
If you wish to switch to a custom accelerator from the CLI without code changes, you can implement the register_accelerators() class method to register your new accelerator under a shorthand name like so:
class XPUAccelerator(Accelerator):
...
@classmethod
def register_accelerators(cls, accelerator_registry):
accelerator_registry.register(
"xpu",
cls,
description=f"XPU Accelerator - optimized for large-scale machine learning.",
)
Now, this is possible:
trainer = Trainer(accelerator="xpu")
Or if you are using the Lightning CLI, for example:
python train.py fit --trainer.accelerator=xpu --trainer.devices=2
Accelerator API¶
The Accelerator base class for Lightning PyTorch. |
|
Accelerator for CPU devices. |
|
Accelerator for NVIDIA CUDA devices. |
|
|
Accelerator for Metal Apple Silicon GPU devices. |
Accelerator for XLA devices, normally TPUs. |
