Introduction Guide¶
PyTorch Lightning provides a very simple template for organizing your PyTorch code. Once you’ve organized it into a LightningModule, it automates most of the training for you.
To illustrate, here’s the typical PyTorch project structure organized in a LightningModule.
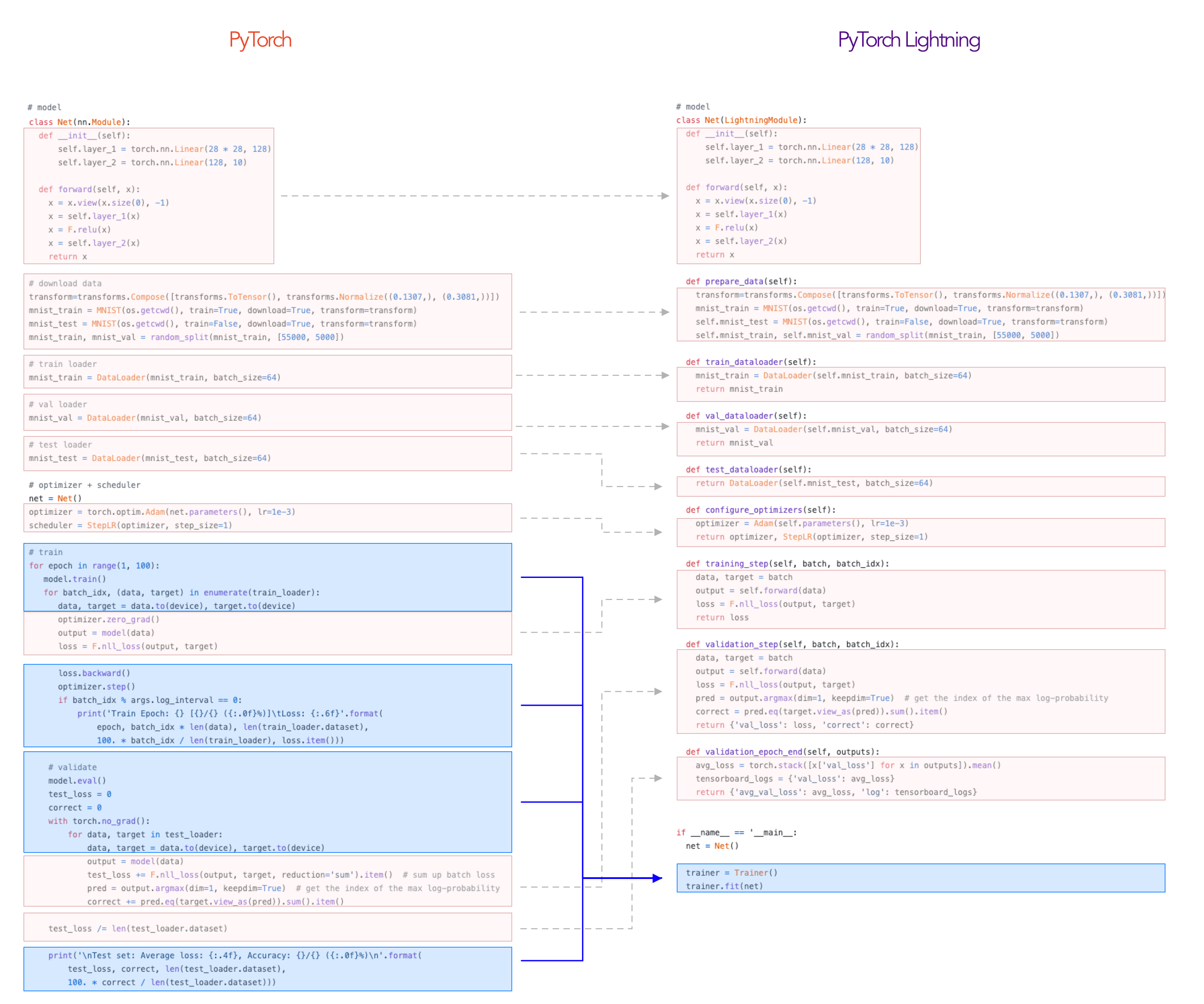
As your project grows in complexity with things like 16-bit precision, distributed training, etc… the part in blue quickly becomes onerous and starts distracting from the core research code.
Goal of this guide¶
This guide walks through the major parts of the library to help you understand what each parts does. But at the end of the day, you write the same PyTorch code… just organize it into the LightningModule template which means you keep ALL the flexibility without having to deal with any of the boilerplate code
To show how Lightning works, we’ll start with an MNIST classifier. We’ll end showing how to use inheritance to very quickly create an AutoEncoder.
Note
Any DL/ML PyTorch project fits into the Lightning structure. Here we just focus on 3 types of research to illustrate.
Installing Lightning¶
Lightning is trivial to install.
conda activate my_env
pip install pytorch-lightning
Or without conda environments, anywhere you can use pip.
pip install pytorch-lightning
Lightning Philosophy¶
Lightning factors DL/ML code into three types:
Research code
Engineering code
Non-essential code
Research code¶
In the MNIST generation example, the research code would be the particular system and how it’s trained (ie: A GAN or VAE). In Lightning, this code is abstracted out by the LightningModule.
l1 = nn.Linear(...)
l2 = nn.Linear(...)
decoder = Decoder()
x1 = l1(x)
x2 = l2(x2)
out = decoder(features, x)
loss = perceptual_loss(x1, x2, x) + CE(out, x)
Engineering code¶
The Engineering code is all the code related to training this system. Things such as early stopping, distribution over GPUs, 16-bit precision, etc. This is normally code that is THE SAME across most projects.
In Lightning, this code is abstracted out by the Trainer.
model.cuda(0)
x = x.cuda(0)
distributed = DistributedParallel(model)
with gpu_zero:
download_data()
dist.barrier()
Non-essential code¶
This is code that helps the research but isn’t relevant to the research code. Some examples might be: 1. Inspect gradients 2. Log to tensorboard.
In Lightning this code is abstracted out by Callbacks.
# log samples
z = Q.rsample()
generated = decoder(z)
self.experiment.log('images', generated)
Elements of a research project¶
Every research project requires the same core ingredients:
A model
Train/val/test data
Optimizer(s)
Training step computations
Validation step computations
Test step computations
The Model¶
The LightningModule provides the structure on how to organize these 5 ingredients.
Let’s first start with the model. In this case we’ll design a 3-layer neural network.
import torch
from torch.nn import functional as F
from torch import nn
from pytorch_lightning.core.lightning import LightningModule
class LitMNIST(LightningModule):
def __init__(self):
super().__init__()
# mnist images are (1, 28, 28) (channels, width, height)
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
def forward(self, x):
batch_size, channels, width, height = x.size()
# (b, 1, 28, 28) -> (b, 1*28*28)
x = x.view(batch_size, -1)
# layer 1
x = self.layer_1(x)
x = torch.relu(x)
# layer 2
x = self.layer_2(x)
x = torch.relu(x)
# layer 3
x = self.layer_3(x)
# probability distribution over labels
x = torch.log_softmax(x, dim=1)
return x
Notice this is a LightningModule instead of a torch.nn.Module. A LightningModule is equivalent to a PyTorch Module except it has added functionality. However, you can use it EXACTLY the same as you would a PyTorch Module.
net = LitMNIST()
x = torch.Tensor(1, 1, 28, 28)
out = net(x)
Out:
torch.Size([1, 10])
Data¶
The Lightning Module organizes your dataloaders and data processing as well. Here’s the PyTorch code for loading MNIST
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
import os
from torchvision import datasets, transforms
# transforms
# prepare transforms standard to MNIST
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# data
mnist_train = MNIST(os.getcwd(), train=True, download=True)
mnist_train = DataLoader(mnist_train, batch_size=64)
When using PyTorch Lightning, we use the exact same code except we organize it into the LightningModule
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
import os
from torchvision import datasets, transforms
class LitMNIST(LightningModule):
def train_dataloader(self):
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=True, download=False,
transform=transform)
return DataLoader(mnist_train, batch_size=64)
Notice the code is exactly the same, except now the training dataloading has been organized by the LightningModule under the train_dataloader method. This is great because if you run into a project that uses Lightning and want to figure out how they prepare their training data you can just look in the train_dataloader method.
Usually though, we want to separate the things that write to disk in data-processing from things like transforms which happen in memory.
class LitMNIST(LightningModule):
def prepare_data(self):
# download only
MNIST(os.getcwd(), train=True, download=True)
def train_dataloader(self):
# no download, just transform
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=True, download=False,
transform=transform)
return DataLoader(mnist_train, batch_size=64)
Doing it in the prepare_data method ensures that when you have multiple GPUs you won’t overwrite the data. This is a contrived example but it gets more complicated with things like NLP or Imagenet.
In general fill these methods with the following:
class LitMNIST(LightningModule):
def prepare_data(self):
# stuff here is done once at the very beginning of training
# before any distributed training starts
# download stuff
# save to disk
# etc...
...
def train_dataloader(self):
# data transforms
# dataset creation
# return a DataLoader
...
Optimizer¶
Next we choose what optimizer to use for training our system. In PyTorch we do it as follows:
from torch.optim import Adam
optimizer = Adam(LitMNIST().parameters(), lr=1e-3)
In Lightning we do the same but organize it under the configure_optimizers method.
class LitMNIST(LightningModule):
def configure_optimizers(self):
return Adam(self.parameters(), lr=1e-3)
Note
The LightningModule itself has the parameters, so pass in self.parameters()
However, if you have multiple optimizers use the matching parameters
class LitMNIST(LightningModule):
def configure_optimizers(self):
return Adam(self.generator(), lr=1e-3), Adam(self.discriminator(), lr=1e-3)
Training step¶
The training step is what happens inside the training loop.
for epoch in epochs:
for batch in data:
# TRAINING STEP
# ....
# TRAINING STEP
loss.backward()
optimizer.step()
optimizer.zero_grad()
In the case of MNIST we do the following
for epoch in epochs:
for batch in data:
# TRAINING STEP START
x, y = batch
logits = model(x)
loss = F.nll_loss(logits, y)
# TRAINING STEP END
loss.backward()
optimizer.step()
optimizer.zero_grad()
In Lightning, everything that is in the training step gets organized under the training_step function in the LightningModule
class LitMNIST(LightningModule):
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
return {'loss': loss}
# return loss (also works)
Again, this is the same PyTorch code except that it has been organized by the LightningModule. This code is not restricted which means it can be as complicated as a full seq-2-seq, RL loop, GAN, etc…
Training¶
So far we defined 4 key ingredients in pure PyTorch but organized the code inside the LightningModule.
Model.
Training data.
Optimizer.
What happens in the training loop.
For clarity, we’ll recall that the full LightningModule now looks like this.
class LitMNIST(LightningModule):
def __init__(self):
super().__init__()
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
def forward(self, x):
batch_size, channels, width, height = x.size()
x = x.view(batch_size, -1)
x = self.layer_1(x)
x = torch.relu(x)
x = self.layer_2(x)
x = torch.relu(x)
x = self.layer_3(x)
x = torch.log_softmax(x, dim=1)
return x
def train_dataloader(self):
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=True, download=False, transform=transform)
return DataLoader(mnist_train, batch_size=64)
def configure_optimizers(self):
return Adam(self.parameters(), lr=1e-3)
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
# add logging
logs = {'loss': loss}
return {'loss': loss, 'log': logs}
Again, this is the same PyTorch code, except that it’s organized by the LightningModule. This organization now lets us train this model
Train on CPU¶
from pytorch_lightning import Trainer
model = LitMNIST()
trainer = Trainer()
trainer.fit(model)
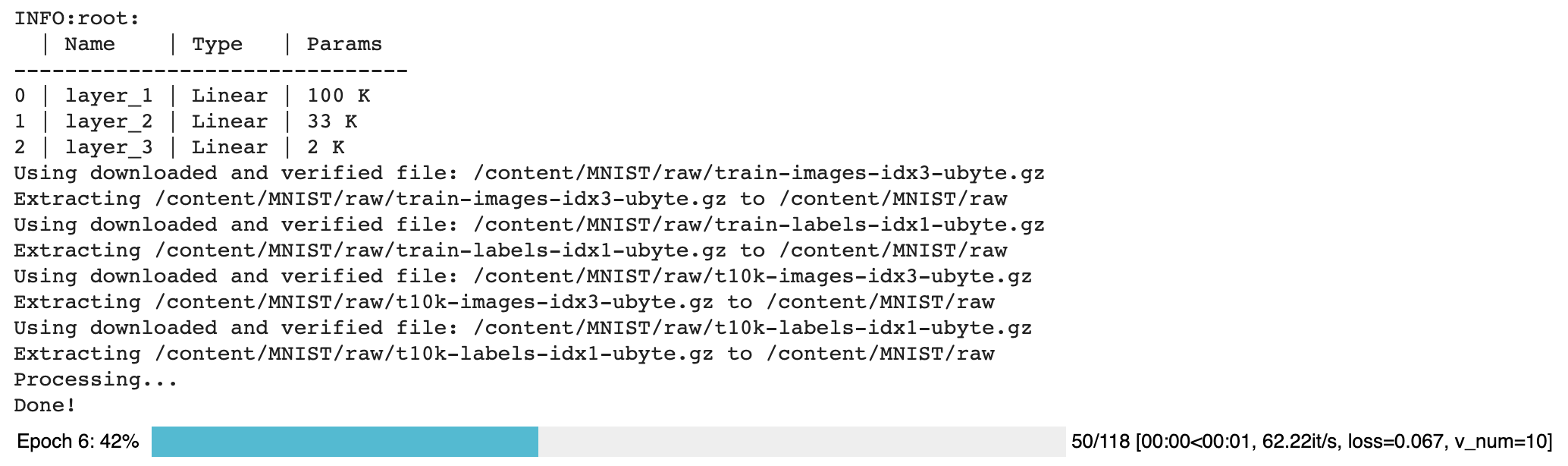
You should see the following weights summary and progress bar

Logging¶
When we added the log key in the return dictionary it went into the built in tensorboard logger. But you could have also logged by calling:
def training_step(self, batch, batch_idx):
# ...
loss = ...
self.logger.summary.scalar('loss', loss)
Which will generate automatic tensorboard logs.
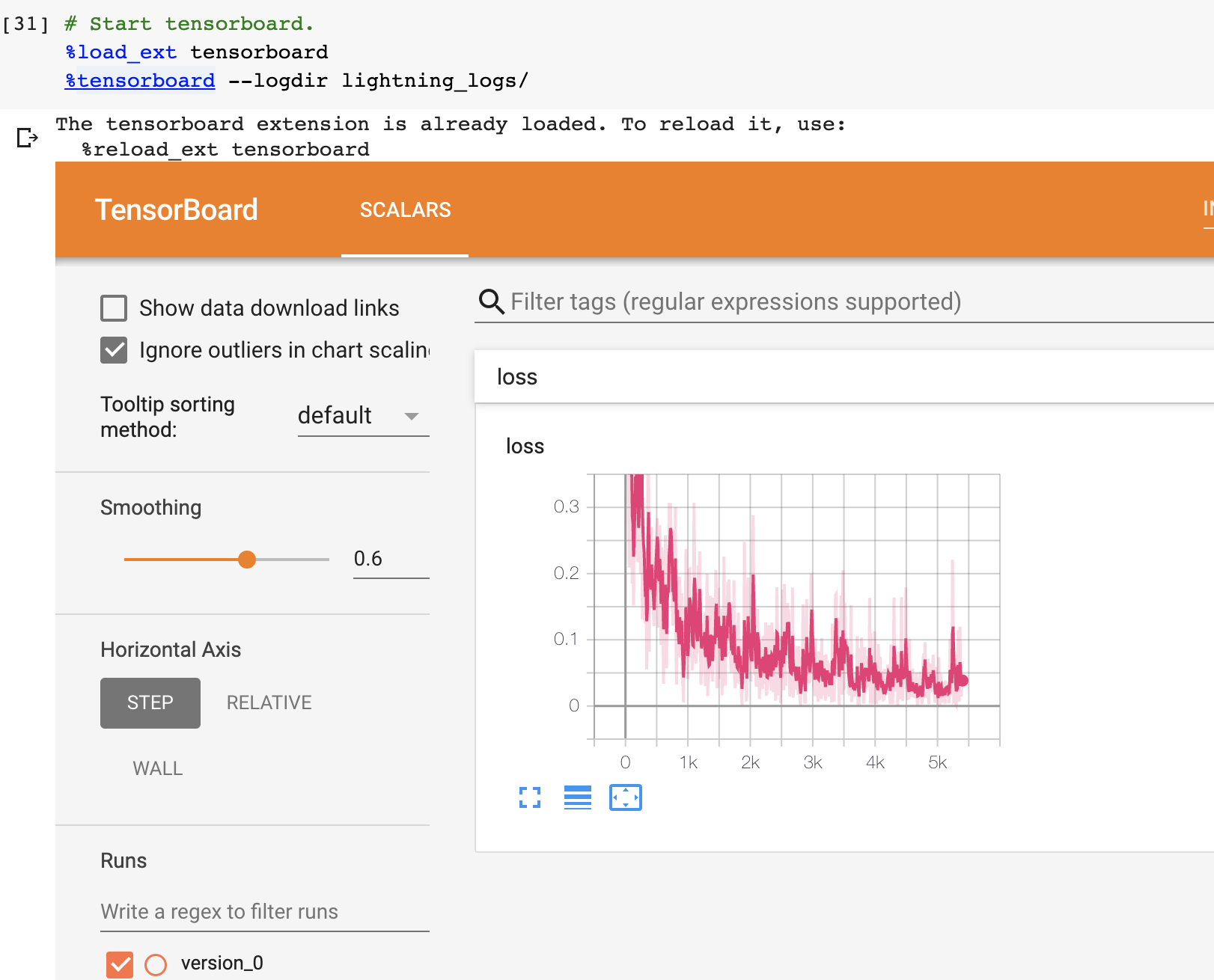
But you can also use any of the number of other loggers we support.
GPU training¶
But the beauty is all the magic you can do with the trainer flags. For instance, to run this model on a GPU:
model = LitMNIST()
trainer = Trainer(gpus=1)
trainer.fit(model)

Multi-GPU training¶
Or you can also train on multiple GPUs.
model = LitMNIST()
trainer = Trainer(gpus=8)
trainer.fit(model)
Or multiple nodes
# (32 GPUs)
model = LitMNIST()
trainer = Trainer(gpus=8, num_nodes=4, distributed_backend='ddp')
trainer.fit(model)
Refer to the distributed computing guide for more details.
TPUs¶
Did you know you can use PyTorch on TPUs? It’s very hard to do, but we’ve worked with the xla team to use their awesome library to get this to work out of the box!
Let’s train on Colab (full demo available here)
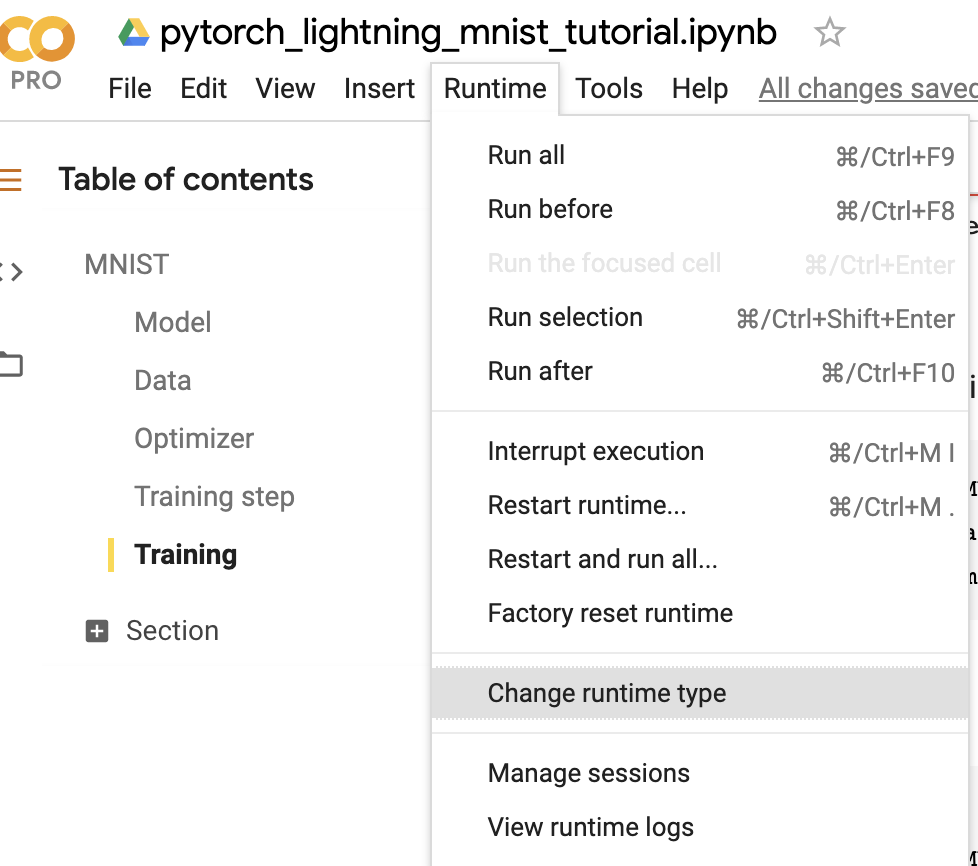
First, change the runtime to TPU (and reinstall lightning).
Next, install the required xla library (adds support for PyTorch on TPUs)
import collections
from datetime import datetime, timedelta
import os
import requests
import threading
_VersionConfig = collections.namedtuple('_VersionConfig', 'wheels,server')
VERSION = "torch_xla==nightly" #@param ["xrt==1.15.0", "torch_xla==nightly"]
CONFIG = {
'xrt==1.15.0': _VersionConfig('1.15', '1.15.0'),
'torch_xla==nightly': _VersionConfig('nightly', 'XRT-dev{}'.format(
(datetime.today() - timedelta(1)).strftime('%Y%m%d'))),
}[VERSION]
DIST_BUCKET = 'gs://tpu-pytorch/wheels'
TORCH_WHEEL = 'torch-{}-cp36-cp36m-linux_x86_64.whl'.format(CONFIG.wheels)
TORCH_XLA_WHEEL = 'torch_xla-{}-cp36-cp36m-linux_x86_64.whl'.format(CONFIG.wheels)
TORCHVISION_WHEEL = 'torchvision-{}-cp36-cp36m-linux_x86_64.whl'.format(CONFIG.wheels)
# Update TPU XRT version
def update_server_xrt():
print('Updating server-side XRT to {} ...'.format(CONFIG.server))
url = 'http://{TPU_ADDRESS}:8475/requestversion/{XRT_VERSION}'.format(
TPU_ADDRESS=os.environ['COLAB_TPU_ADDR'].split(':')[0],
XRT_VERSION=CONFIG.server,
)
print('Done updating server-side XRT: {}'.format(requests.post(url)))
update = threading.Thread(target=update_server_xrt)
update.start()
# Install Colab TPU compat PyTorch/TPU wheels and dependencies
!pip uninstall -y torch torchvision
!gsutil cp "$DIST_BUCKET/$TORCH_WHEEL" .
!gsutil cp "$DIST_BUCKET/$TORCH_XLA_WHEEL" .
!gsutil cp "$DIST_BUCKET/$TORCHVISION_WHEEL" .
!pip install "$TORCH_WHEEL"
!pip install "$TORCH_XLA_WHEEL"
!pip install "$TORCHVISION_WHEEL"
!sudo apt-get install libomp5
update.join()
In distributed training (multiple GPUs and multiple TPU cores) each GPU or TPU core will run a copy of this program. This means that without taking any care you will download the dataset N times which will cause all sorts of issues.
To solve this problem, move the download code to the prepare_data method in the LightningModule. In this method we do all the preparation we need to do once (instead of on every gpu).
class LitMNIST(LightningModule):
def prepare_data(self):
# transform
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# download
mnist_train = MNIST(os.getcwd(), train=True, download=True, transform=transform)
mnist_test = MNIST(os.getcwd(), train=False, download=True, transform=transform)
# train/val split
mnist_train, mnist_val = random_split(mnist_train, [55000, 5000])
# assign to use in dataloaders
self.train_dataset = mnist_train
self.val_dataset = mnist_val
self.test_dataset = mnist_test
def train_dataloader(self):
return DataLoader(self.train_dataset, batch_size=64)
def val_dataloader(self):
return DataLoader(self.val_dataset, batch_size=64)
def test_dataloader(self):
return DataLoader(self.test_dataset, batch_size=64)
The prepare_data method is also a good place to do any data processing that needs to be done only once (ie: download or tokenize, etc…).
Note
Lightning inserts the correct DistributedSampler for distributed training. No need to add yourself!
Now we can train the LightningModule on a TPU without doing anything else!
model = LitMNIST()
trainer = Trainer(num_tpu_cores=8)
trainer.fit(model)
You’ll now see the TPU cores booting up.

Notice the epoch is MUCH faster!
Hyperparameters¶
Lightning has utilities to interact seamlessly with the command line ArgumentParser and plays well with the hyperparameter optimization framework of your choice.
ArgumentParser¶
Lightning is designed to augment a lot of the functionality of the built-in Python ArgumentParser
from argparse import ArgumentParser
parser = ArgumentParser()
parser.add_argument('--layer_1_dim', type=int, default=128)
args = parser.parse_args()
This allows you to call your program like so:
python trainer.py --layer_1_dim 64
Argparser Best Practices¶
It is best practice to layer your arguments in three sections.
Trainer args (gpus, num_nodes, etc…)
Model specific arguments (layer_dim, num_layers, learning_rate, etc…)
Program arguments (data_path, cluster_email, etc…)
We can do this as follows. First, in your LightningModule, define the arguments specific to that module. Remember that data splits or data paths may also be specific to a module (ie: if your project has a model that trains on Imagenet and another on CIFAR-10).
class LitModel(LightningModule):
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument('--encoder_layers', type=int, default=12)
parser.add_argument('--data_path', type=str, default='/some/path')
return parser
Now in your main trainer file, add the Trainer args, the program args, and add the model args
# ----------------
# trainer_main.py
# ----------------
from argparse import ArgumentParser
parser = ArgumentParser()
# add PROGRAM level args
parser.add_argument('--conda_env', type=str, default='some_name')
parser.add_argument('--notification_email', type=str, default='will@email.com')
# add model specific args
parser = LitModel.add_model_specific_args(parser)
# add all the available trainer options to argparse
# ie: now --gpus --num_nodes ... --fast_dev_run all work in the cli
parser = Trainer.add_argparse_args(parser)
hparams = parser.parse_args()
Now you can call run your program like so
python trainer_main.py --gpus 2 --num_nodes 2 --conda_env 'my_env' --encoder_layers 12
Finally, make sure to start the training like so:
# YES
model = LitModel(hparams)
trainer = Trainer.from_argparse_args(hparams, early_stopping_callback=...)
# NO
# model = LitModel(learning_rate=hparams.learning_rate, ...)
# trainer = Trainer(gpus=hparams.gpus, ...)
LightningModule hparams¶
Normally, we don’t hard-code the values to a model. We usually use the command line to modify the network and read those values in the LightningModule
class LitMNIST(LightningModule):
def __init__(self, hparams):
super().__init__()
# do this to save all arguments in any logger (tensorboard)
self.hparams = hparams
self.layer_1 = torch.nn.Linear(28 * 28, hparams.layer_1_dim)
self.layer_2 = torch.nn.Linear(hparams.layer_1_dim, hparams.layer_2_dim)
self.layer_3 = torch.nn.Linear(hparams.layer_2_dim, 10)
def train_dataloader(self):
return DataLoader(mnist_train, batch_size=self.hparams.batch_size)
def configure_optimizers(self):
return Adam(self.parameters(), lr=self.hparams.learning_rate)
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument('--layer_1_dim', type=int, default=128)
parser.add_argument('--layer_2_dim', type=int, default=256)
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--learning_rate', type=float, default=0.002)
return parser
Now pass in the params when you init your model
parser = ArgumentParser()
parser = LitMNIST.add_model_specific_args(parser)
hparams = parser.parse_args()
model = LitMNIST(hparams)
The line self.hparams = hparams is very special. This line assigns your hparams to the LightningModule. This does two things:
It adds them automatically to TensorBoard logs under the hparams tab.
Lightning will save those hparams to the checkpoint and use them to restore the module correctly.
Trainer args¶
To recap, add ALL possible trainer flags to the argparser and init the Trainer this way
parser = ArgumentParser()
parser = Trainer.add_argparse_args(parser)
hparams = parser.parse_args()
trainer = Trainer.from_argparse_args(hparams)
# or if you need to pass in callbacks
trainer = Trainer.from_argparse_args(hparams, checkpoint_callback=..., callbacks=[...])
Multiple Lightning Modules¶
We often have multiple Lightning Modules where each one has different arguments. Instead of polluting the main.py file, the LightningModule lets you define arguments for each one.
class LitMNIST(LightningModule):
def __init__(self, hparams):
super().__init__()
self.layer_1 = torch.nn.Linear(28 * 28, hparams.layer_1_dim)
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser])
parser.add_argument('--layer_1_dim', type=int, default=128)
return parser
class GoodGAN(LightningModule):
def __init__(self, hparams):
super().__init__()
self.encoder = Encoder(layers=hparams.encoder_layers)
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser])
parser.add_argument('--encoder_layers', type=int, default=12)
return parser
Now we can allow each model to inject the arguments it needs in the main.py
def main(args):
# pick model
if args.model_name == 'gan':
model = GoodGAN(hparams=args)
elif args.model_name == 'mnist':
model = LitMNIST(hparams=args)
model = LitMNIST(hparams=args)
trainer = Trainer.from_argparse_args(args)
trainer.fit(model)
if __name__ == '__main__':
parser = ArgumentParser()
parser = Trainer.add_argparse_args(parser)
# figure out which model to use
parser.add_argument('--model_name', type=str, default='gan', help='gan or mnist')
# THIS LINE IS KEY TO PULL THE MODEL NAME
temp_args, _ = parser.parse_known_args()
# let the model add what it wants
if temp_args.model_name == 'gan':
parser = GoodGAN.add_model_specific_args(parser)
elif temp_args.model_name == 'mnist':
parser = LitMNIST.add_model_specific_args(parser)
args = parser.parse_args()
# train
main(args)
and now we can train MNIST or the GAN using the command line interface!
$ python main.py --model_name gan --encoder_layers 24
$ python main.py --model_name mnist --layer_1_dim 128
Validating¶
For most cases, we stop training the model when the performance on a validation split of the data reaches a minimum.
Just like the training_step, we can define a validation_step to check whatever metrics we care about, generate samples or add more to our logs.
for epoch in epochs:
for batch in data:
# ...
# train
# validate
outputs = []
for batch in val_data:
x, y = batch # validation_step
y_hat = model(x) # validation_step
loss = loss(y_hat, x) # validation_step
outputs.append({'val_loss': loss}) # validation_step
full_loss = outputs.mean() # validation_epoch_end
Since the validation_step processes a single batch, in Lightning we also have a validation_epoch_end method which allows you to compute statistics on the full dataset after an epoch of validation data and not just the batch.
In addition, we define a val_dataloader method which tells the trainer what data to use for validation. Notice we split the train split of MNIST into train, validation. We also have to make sure to do the sample split in the train_dataloader method.
class LitMNIST(LightningModule):
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
return {'val_loss': loss}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss}
return {'val_loss': avg_loss, 'log': tensorboard_logs}
def val_dataloader(self):
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=True, download=False,
transform=transform)
_, mnist_val = random_split(mnist_train, [55000, 5000])
mnist_val = DataLoader(mnist_val, batch_size=64)
return mnist_val
Again, we’ve just organized the regular PyTorch code into two steps, the validation_step method which operates on a single batch and the validation_epoch_end method to compute statistics on all batches.
If you have these methods defined, Lightning will call them automatically. Now we can train while checking the validation set.
from pytorch_lightning import Trainer
model = LitMNIST()
trainer = Trainer(num_tpu_cores=8)
trainer.fit(model)
You may have noticed the words Validation sanity check logged. This is because Lightning runs 5 batches of validation before starting to train. This is a kind of unit test to make sure that if you have a bug in the validation loop, you won’t need to potentially wait a full epoch to find out.
Note
Lightning disables gradients, puts model in eval mode and does everything needed for validation.
Testing¶
Once our research is done and we’re about to publish or deploy a model, we normally want to figure out how it will generalize in the “real world.” For this, we use a held-out split of the data for testing.
Just like the validation loop, we define exactly the same steps for testing:
test_step
test_epoch_end
test_dataloader
class LitMNIST(LightningModule):
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
return {'val_loss': loss}
def test_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss}
return {'val_loss': avg_loss, 'log': tensorboard_logs}
def test_dataloader(self):
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=False, download=False, transform=transform)
_, mnist_val = random_split(mnist_train, [55000, 5000])
mnist_val = DataLoader(mnist_val, batch_size=64)
return mnist_val
However, to make sure the test set isn’t used inadvertently, Lightning has a separate API to run tests. Once you train your model simply call .test().
from pytorch_lightning import Trainer
model = LitMNIST()
trainer = Trainer(num_tpu_cores=8)
trainer.fit(model)
# run test set
trainer.test()
Out:
--------------------------------------------------------------
TEST RESULTS
{'test_loss': tensor(1.1703, device='cuda:0')}
--------------------------------------------------------------
You can also run the test from a saved lightning model
model = LitMNIST.load_from_checkpoint(PATH)
trainer = Trainer(num_tpu_cores=8)
trainer.test(model)
Note
Lightning disables gradients, puts model in eval mode and does everything needed for testing.
Warning
.test() is not stable yet on TPUs. We’re working on getting around the multiprocessing challenges.
Predicting¶
Again, a LightningModule is exactly the same as a PyTorch module. This means you can load it and use it for prediction.
model = LitMNIST.load_from_checkpoint(PATH)
x = torch.Tensor(1, 1, 28, 28)
out = model(x)
On the surface, it looks like forward and training_step are similar. Generally, we want to make sure that what we want the model to do is what happens in the forward. whereas the training_step likely calls forward from within it.
class MNISTClassifier(LightningModule):
def forward(self, x):
batch_size, channels, width, height = x.size()
x = x.view(batch_size, -1)
x = self.layer_1(x)
x = torch.relu(x)
x = self.layer_2(x)
x = torch.relu(x)
x = self.layer_3(x)
x = torch.log_softmax(x, dim=1)
return x
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
return loss
model = MNISTClassifier()
x = mnist_image()
logits = model(x)
In this case, we’ve set this LightningModel to predict logits. But we could also have it predict feature maps:
class MNISTRepresentator(LightningModule):
def forward(self, x):
batch_size, channels, width, height = x.size()
x = x.view(batch_size, -1)
x = self.layer_1(x)
x1 = torch.relu(x)
x = self.layer_2(x1)
x2 = torch.relu(x)
x3 = self.layer_3(x2)
return [x, x1, x2, x3]
def training_step(self, batch, batch_idx):
x, y = batch
out, l1_feats, l2_feats, l3_feats = self(x)
logits = torch.log_softmax(out, dim=1)
ce_loss = F.nll_loss(logits, y)
loss = perceptual_loss(l1_feats, l2_feats, l3_feats) + ce_loss
return loss
model = MNISTRepresentator.load_from_checkpoint(PATH)
x = mnist_image()
feature_maps = model(x)
Or maybe we have a model that we use to do generation
class LitMNISTDreamer(LightningModule):
def forward(self, z):
imgs = self.decoder(z)
return imgs
def training_step(self, batch, batch_idx):
x, y = batch
representation = self.encoder(x)
imgs = self(representation)
loss = perceptual_loss(imgs, x)
return loss
model = LitMNISTDreamer.load_from_checkpoint(PATH)
z = sample_noise()
generated_imgs = model(z)
How you split up what goes in forward vs training_step depends on how you want to use this model for prediction.
Extensibility¶
Although lightning makes everything super simple, it doesn’t sacrifice any flexibility or control. Lightning offers multiple ways of managing the training state.
Training overrides¶
Any part of the training, validation and testing loop can be modified. For instance, if you wanted to do your own backward pass, you would override the default implementation
def backward(self, use_amp, loss, optimizer):
if use_amp:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
With your own
class LitMNIST(LightningModule):
def backward(self, use_amp, loss, optimizer):
# do a custom way of backward
loss.backward(retain_graph=True)
Or if you wanted to initialize ddp in a different way than the default one
def configure_ddp(self, model, device_ids):
# Lightning DDP simply routes to test_step, val_step, etc...
model = LightningDistributedDataParallel(
model,
device_ids=device_ids,
find_unused_parameters=True
)
return model
you could do your own:
class LitMNIST(LightningModule):
def configure_ddp(self, model, device_ids):
model = Horovod(model)
# model = Ray(model)
return model
Every single part of training is configurable this way. For a full list look at LightningModule.
Callbacks¶
Another way to add arbitrary functionality is to add a custom callback for hooks that you might care about
from pytorch_lightning.callbacks import Callback
class MyPrintingCallback(Callback):
def on_init_start(self, trainer):
print('Starting to init trainer!')
def on_init_end(self, trainer):
print('Trainer is init now')
def on_train_end(self, trainer, pl_module):
print('do something when training ends')
And pass the callbacks into the trainer
trainer = Trainer(callbacks=[MyPrintingCallback()])
Note
See full list of 12+ hooks in the Callbacks.
Child Modules¶
Research projects tend to test different approaches to the same dataset. This is very easy to do in Lightning with inheritance.
For example, imagine we now want to train an Autoencoder to use as a feature extractor for MNIST images. Recall that LitMNIST already defines all the dataloading etc… The only things that change in the Autoencoder model are the init, forward, training, validation and test step.
class Encoder(torch.nn.Module):
pass
class Decoder(torch.nn.Module):
pass
class AutoEncoder(LitMNIST):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, x):
generated = self.decoder(x)
def training_step(self, batch, batch_idx):
x, _ = batch
representation = self.encoder(x)
x_hat = self(representation)
loss = MSE(x, x_hat)
return loss
def validation_step(self, batch, batch_idx):
return self._shared_eval(batch, batch_idx, 'val')
def test_step(self, batch, batch_idx):
return self._shared_eval(batch, batch_idx, 'test')
def _shared_eval(self, batch, batch_idx, prefix):
x, y = batch
representation = self.encoder(x)
x_hat = self(representation)
loss = F.nll_loss(logits, y)
return {f'{prefix}_loss': loss}
and we can train this using the same trainer
autoencoder = AutoEncoder()
trainer = Trainer()
trainer.fit(autoencoder)
And remember that the forward method is to define the practical use of a LightningModule. In this case, we want to use the AutoEncoder to extract image representations
some_images = torch.Tensor(32, 1, 28, 28)
representations = autoencoder(some_images)
Transfer Learning¶
Using Pretrained Models¶
Sometimes we want to use a LightningModule as a pretrained model. This is fine because a LightningModule is just a torch.nn.Module!
Note
Remember that a LightningModule is EXACTLY a torch.nn.Module but with more capabilities.
Let’s use the AutoEncoder as a feature extractor in a separate model.
class Encoder(torch.nn.Module):
...
class AutoEncoder(LightningModule):
def __init__(self):
self.encoder = Encoder()
self.decoder = Decoder()
class CIFAR10Classifier(LightningModule):
def __init__(self):
# init the pretrained LightningModule
self.feature_extractor = AutoEncoder.load_from_checkpoint(PATH)
self.feature_extractor.freeze()
# the autoencoder outputs a 100-dim representation and CIFAR-10 has 10 classes
self.classifier = nn.Linear(100, 10)
def forward(self, x):
representations = self.feature_extractor(x)
x = self.classifier(representations)
...
We used our pretrained Autoencoder (a LightningModule) for transfer learning!
Example: Imagenet (computer Vision)¶
import torchvision.models as models
class ImagenetTransferLearning(LightningModule):
def __init__(self):
# init a pretrained resnet
num_target_classes = 10
self.feature_extractor = models.resnet50(
pretrained=True,
num_classes=num_target_classes)
self.feature_extractor.eval()
# use the pretrained model to classify cifar-10 (10 image classes)
self.classifier = nn.Linear(2048, num_target_classes)
def forward(self, x):
representations = self.feature_extractor(x)
x = self.classifier(representations)
...
Finetune
model = ImagenetTransferLearning()
trainer = Trainer()
trainer.fit(model)
And use it to predict your data of interest
model = ImagenetTransferLearning.load_from_checkpoint(PATH)
model.freeze()
x = some_images_from_cifar10()
predictions = model(x)
We used a pretrained model on imagenet, finetuned on CIFAR-10 to predict on CIFAR-10. In the non-academic world we would finetune on a tiny dataset you have and predict on your dataset.
Example: BERT (NLP)¶
Lightning is completely agnostic to what’s used for transfer learning so long as it is a torch.nn.Module subclass.
Here’s a model that uses Huggingface transformers.
class BertMNLIFinetuner(LightningModule):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained('bert-base-cased', output_attentions=True)
self.W = nn.Linear(bert.config.hidden_size, 3)
self.num_classes = 3
def forward(self, input_ids, attention_mask, token_type_ids):
h, _, attn = self.bert(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
h_cls = h[:, 0]
logits = self.W(h_cls)
return logits, attn
