Learning Rate Finder¶
For training deep neural networks, selecting a good learning rate is essential for both better performance and faster convergence. Even optimizers such as Adam that are self-adjusting the learning rate can benefit from more optimal choices.
To reduce the amount of guesswork concerning choosing a good initial learning rate, a learning rate finder can be used. As described in this paper a learning rate finder does a small run where the learning rate is increased after each processed batch and the corresponding loss is logged. The result of this is a lr vs. loss plot that can be used as guidance for choosing a optimal initial lr.
Warnings: - For the moment, this feature only works with models having a single optimizer. - LR support for DDP is not implemented yet, it is comming soon.
Using Lightnings build-in LR finder¶
In the most basic use case, this feature can be enabled during trainer construction
with Trainer(auto_lr_find=True). When .fit(model) is called, the lr finder
will automatically be run before any training is done. The lr that is found
and used will be written to the console and logged together with all other
hyperparameters of the model.
# default, no automatic learning rate finder
trainer = Trainer(auto_lr_find=True)
When the lr or learning_rate key in hparams exists, this flag sets your learning_rate.
In both cases, if the respective fields are not found, an error will be thrown.
class LitModel(LightningModule):
def __init__(self, hparams):
self.hparams = hparams
def configure_optimizers(self):
return Adam(self.parameters(), lr=self.hparams.lr|self.hparams.learning_rate)
# finds learning rate automatically
# sets hparams.lr or hparams.learning_rate to that learning rate
trainer = Trainer(auto_lr_find=True)
To use an arbitrary value set it in the parameter.
# to set to your own hparams.my_value
trainer = Trainer(auto_lr_find='my_value')
Under the hood, when you call fit, this is what happens.
Run learning rate finder.
Run actual fit.
# when you call .fit() this happens
# 1. find learning rate
# 2. actually run fit
trainer.fit(model)
If you want to inspect the results of the learning rate finder before doing any
actual training or just play around with the parameters of the algorithm, this
can be done by invoking the lr_find method of the trainer. A typical example
of this would look like
model = MyModelClass(hparams)
trainer = Trainer()
# Run learning rate finder
lr_finder = trainer.lr_find(model)
# Results can be found in
lr_finder.results
# Plot with
fig = lr_finder.plot(suggest=True)
fig.show()
# Pick point based on plot, or get suggestion
new_lr = lr_finder.suggestion()
# update hparams of the model
model.hparams.lr = new_lr
# Fit model
trainer.fit(model)
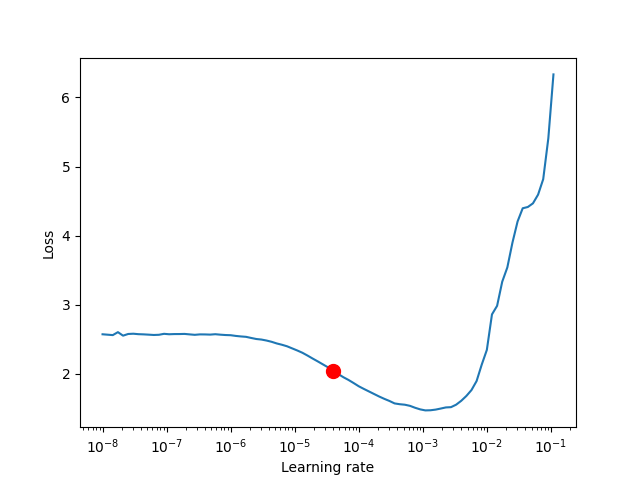
The figure produced by lr_finder.plot() should look something like the figure
below. It is recommended to not pick the learning rate that achives the lowest
loss, but instead something in the middle of the sharpest downward slope (red point).
This is the point returned py lr_finder.suggestion().
The parameters of the algorithm can be seen below.
-
class
pytorch_lightning.trainer.lr_finder.TrainerLRFinderMixin[source] Bases:
abc.ABC-
_run_lr_finder_internally(model)[source] Call lr finder internally during Trainer.fit()
-
lr_find(model, train_dataloader=None, val_dataloaders=None, min_lr=1e-08, max_lr=1, num_training=100, mode='exponential', early_stop_threshold=4.0, num_accumulation_steps=None)[source] lr_find enables the user to do a range test of good initial learning rates, to reduce the amount of guesswork in picking a good starting learning rate.
- Parameters
model¶ (
LightningModule) – Model to do range testing fortrain_dataloader¶ (
Optional[DataLoader]) – A PyTorch DataLoader with training samples. If the model has a predefined train_dataloader method this will be skipped.mode¶ (
str) – search strategy, either ‘linear’ or ‘exponential’. If set to ‘linear’ the learning rate will be searched by linearly increasing after each batch. If set to ‘exponential’, will increase learning rate exponentially.early_stop_threshold¶ (
float) – threshold for stopping the search. If the loss at any point is larger than early_stop_threshold*best_loss then the search is stopped. To disable, set to None.num_accumulation_steps¶ – deprepecated, number of batches to calculate loss over. Set trainer argument
accumulate_grad_batchesinstead.
Example:
# Setup model and trainer model = MyModelClass(hparams) trainer = pl.Trainer() # Run lr finder lr_finder = trainer.lr_find(model, ...) # Inspect results fig = lr_finder.plot(); fig.show() suggested_lr = lr_finder.suggestion() # Overwrite lr and create new model hparams.lr = suggested_lr model = MyModelClass(hparams) # Ready to train with new learning rate trainer.fit(model)
-
abstract
restore(*args)[source] Warning: this is just empty shell for code implemented in other class.
-
abstract
save_checkpoint(*args)[source] Warning: this is just empty shell for code implemented in other class.
-
