pytorch_lightning.metrics.sklearns module¶
-
class
pytorch_lightning.metrics.sklearns.AUC(reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCalculates the Area Under the Curve using the trapoezoidal rule
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = AUC() >>> metric(y_pred, y_true) tensor([4.])
- Parameters
-
class
pytorch_lightning.metrics.sklearns.AUROC(average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute Area Under the Curve (AUC) from prediction scores
Note
this implementation is restricted to the binary classification task or multilabel classification task in label indicator format.
- Parameters
If None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data:
If ‘micro’: Calculate metrics globally by considering each element of the label indicator matrix as a label.
If ‘macro’: Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
If ‘weighted’: Calculate metrics for each label, and find their average, weighted by support (the number of true instances for each label).
If ‘samples’: Calculate metrics for each instance, and find their average.
reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.Accuracy(normalize=True, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCalculates the Accuracy Score
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = Accuracy() >>> metric(y_pred, y_true) tensor([0.7500])
- Parameters
normalize¶ (
bool) – IfFalse, return the number of correctly classified samples. Otherwise, return the fraction of correctly classified samples.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.AveragePrecision(average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCalculates the average precision (AP) score.
- Parameters
If None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data:
If ‘micro’: Calculate metrics globally by considering each element of the label indicator matrix as a label.
If ‘macro’: Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
If ‘weighted’: Calculate metrics for each label, and find their average, weighted by support (the number of true instances for each label).
If ‘samples’: Calculate metrics for each instance, and find their average.
reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.ConfusionMatrix(labels=None, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute confusion matrix to evaluate the accuracy of a classification By definition a confusion matrix
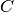 is such that
is such that 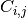 is equal to the number of observations known to be in group
is equal to the number of observations known to be in group 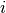 but
predicted to be in group
but
predicted to be in group 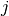 .
.Example
>>> y_pred = torch.tensor([0, 1, 2, 1]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = ConfusionMatrix() >>> metric(y_pred, y_true) tensor([[1., 0., 0.], [0., 1., 0.], [0., 1., 1.]])
- Parameters
labels¶ (
Optional[Sequence]) – List of labels to index the matrix. This may be used to reorder or select a subset of labels. If none is given, those that appear at least once iny_trueory_predare used in sorted order.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.F1(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute the F1 score, also known as balanced F-score or F-measure The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal. The formula for the F1 score is:
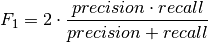
In the multi-class and multi-label case, this is the weighted average of the F1 score of each class.
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = F1() >>> metric(y_pred, y_true) tensor([0.6667])
- References
- Parameters
pos_label¶ (
Union[str,int]) – The class to report ifaverage='binary'.This parameter is required for multiclass/multilabel targets. If
None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data:'binary': Only report results for the class specified bypos_label. This is applicable only if targets (y_{true,pred}) are binary.'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.'weighted': Calculate metrics for each label, and find their average, weighted by support (the number of true instances for each label). This alters ‘macro’ to account for label imbalance; it can result in an F-score that is not between precision and recall.'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification where this differs fromaccuracy_score()).
Note that if
pos_labelis given in binary classification with average != ‘binary’, only that positive class is reported. This behavior is deprecated and will change in version 0.18.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.FBeta(beta, labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute the F-beta score. The beta parameter determines the weight of precision in the combined score.
beta < 1lends more weight to precision, whilebeta > 1favors recall (beta -> 0considers only precision,beta -> infonly recall).Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = FBeta(beta=0.25) >>> metric(y_pred, y_true) tensor([0.7361])
References
[1] R. Baeza-Yates and B. Ribeiro-Neto (2011). Modern Information Retrieval. Addison Wesley, pp. 327-328.
- Parameters
pos_label¶ (
Union[str,int]) – The class to report ifaverage='binary'.This parameter is required for multiclass/multilabel targets. If
None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data:'binary': Only report results for the class specified bypos_label. This is applicable only if targets (y_{true,pred}) are binary.'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.'weighted': Calculate metrics for each label, and find their average, weighted by support (the number of true instances for each label). This alters ‘macro’ to account for label imbalance; it can result in an F-score that is not between precision and recall.'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification where this differs fromaccuracy_score()).
Note that if
pos_labelis given in binary classification with average != ‘binary’, only that positive class is reported. This behavior is deprecated and will change in version 0.18.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.Precision(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute the precision The precision is the ratio
tp / (tp + fp)wheretpis the number of true positives andfpthe number of false positives. The precision is intuitively the ability of the classifier not to label as positive a sample that is negative. The best value is 1 and the worst value is 0.Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = Precision() >>> metric(y_pred, y_true) tensor([0.7500])
- Parameters
pos_label¶ (
Union[str,int]) – The class to report ifaverage='binary'.This parameter is required for multiclass/multilabel targets. If
None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data:'binary': Only report results for the class specified bypos_label. This is applicable only if targets (y_{true,pred}) are binary.'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.'weighted': Calculate metrics for each label, and find their average, weighted by support (the number of true instances for each label). This alters ‘macro’ to account for label imbalance; it can result in an F-score that is not between precision and recall.'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification where this differs fromaccuracy_score()).
Note that if
pos_labelis given in binary classification with average != ‘binary’, only that positive class is reported. This behavior is deprecated and will change in version 0.18.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.PrecisionRecallCurve(pos_label=1, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute precision-recall pairs for different probability thresholds
Note
This implementation is restricted to the binary classification task.
The precision is the ratio
tp / (tp + fp)wheretpis the number of true positives andfpthe number of false positives. The precision is intuitively the ability of the classifier not to label as positive a sample that is negative. The recall is the ratiotp / (tp + fn)wheretpis the number of true positives andfnthe number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples. The last precision and recall values are 1. and 0. respectively and do not have a corresponding threshold. This ensures that the graph starts on the x axis.- Parameters
pos_label¶ (
Union[str,int]) – The class to report ifaverage='binary'.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
forward(probas_pred, y_true, sample_weight=None)[source]¶ - Parameters
- Returns
- Precision values such that element i is the precision of
predictions with score >= thresholds[i] and the last element is 1.
- recall:
Decreasing recall values such that element i is the recall of predictions with score >= thresholds[i] and the last element is 0.
- thresholds:
Increasing thresholds on the decision function used to compute precision and recall.
- Return type
precision
-
class
pytorch_lightning.metrics.sklearns.ROC(pos_label=1, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute Receiver operating characteristic (ROC)
Note
this implementation is restricted to the binary classification task.
Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = ROC() >>> fps, tps = metric(y_pred, y_true) >>> fps tensor([0.0000, 0.3333, 0.6667, 0.6667, 1.0000]) >>> tps tensor([0., 0., 0., 1., 1.])
References
- Parameters
-
forward(y_score, y_true, sample_weight=None)[source]¶ - Parameters
- Returns
- Increasing false positive rates such that element i is the false
positive rate of predictions with score >= thresholds[i].
- tpr:
Increasing true positive rates such that element i is the true positive rate of predictions with score >= thresholds[i].
- thresholds:
Decreasing thresholds on the decision function used to compute fpr and tpr. thresholds[0] represents no instances being predicted and is arbitrarily set to max(y_score) + 1.
- Return type
fpr
-
class
pytorch_lightning.metrics.sklearns.Recall(labels=None, pos_label=1, average='macro', reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM)[source]¶ Bases:
pytorch_lightning.metrics.sklearns.SklearnMetricCompute the recall The recall is the ratio
tp / (tp + fn)wheretpis the number of true positives andfnthe number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples. The best value is 1 and the worst value is 0.Example
>>> y_pred = torch.tensor([0, 1, 2, 3]) >>> y_true = torch.tensor([0, 1, 2, 2]) >>> metric = Recall() >>> metric(y_pred, y_true) tensor([0.6250])
- Parameters
pos_label¶ (
Union[str,int]) – The class to report ifaverage='binary'.This parameter is required for multiclass/multilabel targets. If
None, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data:'binary': Only report results for the class specified bypos_label. This is applicable only if targets (y_{true,pred}) are binary.'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.'weighted': Calculate metrics for each label, and find their average, weighted by support (the number of true instances for each label). This alters ‘macro’ to account for label imbalance; it can result in an F-score that is not between precision and recall.'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification where this differs fromaccuracy_score()).
Note that if
pos_labelis given in binary classification with average != ‘binary’, only that positive class is reported. This behavior is deprecated and will change in version 0.18.reduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.
-
class
pytorch_lightning.metrics.sklearns.SklearnMetric(metric_name, reduce_group=torch.distributed.group.WORLD, reduce_op=torch.distributed.ReduceOp.SUM, **kwargs)[source]¶ Bases:
pytorch_lightning.metrics.metric.NumpyMetricBridge between PyTorch Lightning and scikit-learn metrics
Warning
Every metric call will cause a GPU synchronization, which may slow down your code
Note
The order of targets and predictions may be different from the order typically used in PyTorch
- Parameters
metric_name¶ (
str) – the metric name to import and compute from scikit-learn.metricsreduce_group¶ (
Any) – the process group for DDP reduces (only needed for DDP training). Defaults to all processes (world)reduce_op¶ (
Any) – the operation to perform during reduction within DDP (only needed for DDP training). Defaults to sum.**kwargs¶ – additonal keyword arguments (will be forwarded to metric call)
