Metrics¶
pytorch_lightning.metrics is a Metrics API created for easy metric development and usage in
PyTorch and PyTorch Lightning. It is rigorously tested for all edge cases and includes a growing list of
common metric implementations.
The metrics API provides update(), compute(), reset() functions to the user. The metric base class inherits
nn.Module which allows us to call metric(...) directly. The forward() method of the base Metric class
serves the dual purpose of calling update() on its input and simultaneously returning the value of the metric over the
provided input.
These metrics work with DDP in PyTorch and PyTorch Lightning by default. When .compute() is called in
distributed mode, the internal state of each metric is synced and reduced across each process, so that the
logic present in .compute() is applied to state information from all processes.
The example below shows how to use a metric in your LightningModule:
def __init__(self):
...
self.accuracy = pl.metrics.Accuracy()
def training_step(self, batch, batch_idx):
x, y = batch
preds = self(x)
...
# log step metric
self.log('train_acc_step', self.accuracy(preds, y))
...
def training_epoch_end(self, outs):
# log epoch metric
self.log('train_acc_epoch', self.accuracy.compute())
Metric objects can also be directly logged, in which case Lightning will log
the metric based on on_step and on_epoch flags present in self.log(...).
If on_epoch is True, the logger automatically logs the end of epoch metric value by calling
.compute().
Note
sync_dist, sync_dist_op, sync_dist_group, reduce_fx and tbptt_reduce_fx
flags from self.log(...) don’t affect the metric logging in any manner. The metric class
contains its own distributed synchronization logic.
This however is only true for metrics that inherit the base class Metric,
and thus the functional metric API provides no support for in-built distributed synchronization
or reduction functions.
def __init__(self):
...
self.train_acc = pl.metrics.Accuracy()
self.valid_acc = pl.metrics.Accuracy()
def training_step(self, batch, batch_idx):
x, y = batch
preds = self(x)
...
self.train_acc(preds, y)
self.log('train_acc', self.train_acc, on_step=True, on_epoch=False)
def validation_step(self, batch, batch_idx):
logits = self(x)
...
self.valid_acc(logits, y)
self.log('valid_acc', self.valid_acc, on_step=True, on_epoch=True)
Note
If using metrics in data parallel mode (dp), the metric update/logging should be done
in the <mode>_step_end method (where <mode> is either training, validation
or test). This is due to metric states else being destroyed after each forward pass,
leading to wrong accumulation. In practice do the following:
def training_step(self, batch, batch_idx):
data, target = batch
preds = self(data)
...
return {'loss' : loss, 'preds' : preds, 'target' : target}
def training_step_end(self, outputs):
#update and log
self.metric(outputs['preds'], outputs['target'])
self.log('metric', self.metric)
This metrics API is independent of PyTorch Lightning. Metrics can directly be used in PyTorch as shown in the example:
from pytorch_lightning import metrics
train_accuracy = metrics.Accuracy()
valid_accuracy = metrics.Accuracy(compute_on_step=False)
for epoch in range(epochs):
for x, y in train_data:
y_hat = model(x)
# training step accuracy
batch_acc = train_accuracy(y_hat, y)
for x, y in valid_data:
y_hat = model(x)
valid_accuracy(y_hat, y)
# total accuracy over all training batches
total_train_accuracy = train_accuracy.compute()
# total accuracy over all validation batches
total_valid_accuracy = valid_accuracy.compute()
Note
Metrics contain internal states that keep track of the data seen so far. Do not mix metric states across training, validation and testing. It is highly recommended to re-initialize the metric per mode as shown in the examples above.
Note
Metric states are not added to the models state_dict by default.
To change this, after initializing the metric, the method .persistent(mode) can
be used to enable (mode=True) or disable (mode=False) this behaviour.
Metrics and devices¶
Metrics are simple subclasses of Module and their metric states behave
similar to buffers and parameters of modules. This means that metrics states should
be moved to the same device as the input of the metric:
import torch
from pytorch_lightning.metrics import Accuracy
target = torch.tensor([1, 1, 0, 0], device=torch.device("cuda", 0))
preds = torch.tensor([0, 1, 0, 0], device=torch.device("cuda", 0))
# Metric states are always initialized on cpu, and needs to be moved to
# the correct device
confmat = Accuracy(num_classes=2).to(torch.device("cuda", 0))
out = confmat(preds, target)
print(out.device) # cuda:0
However, when properly defined inside a LightningModule
, Lightning will automatically move the metrics to the same device as the data. Being
properly defined means that the metric is correctly identified as a child module of the
model (check .children() attribute of the model). Therefore, metrics cannot be placed
in native python list and dict, as they will not be correctly identified
as child modules. Instead of list use ModuleList and instead of
dict use ModuleDict.
class MyModule(LightningModule):
def __init__(self):
...
# valid ways metrics will be identified as child modules
self.metric1 = pl.metrics.Accuracy()
self.metric2 = torch.nn.ModuleList(pl.metrics.Accuracy())
self.metric3 = torch.nn.ModuleDict({'accuracy': Accuracy()})
def training_step(self, batch, batch_idx):
# all metrics will be on the same device as the input batch
data, target = batch
preds = self(data)
...
val1 = self.metric1(preds, target)
val2 = self.metric2[0](preds, target)
val3 = self.metric3['accuracy'](preds, target)
Implementing a Metric¶
To implement your custom metric, subclass the base Metric class and implement the following methods:
__init__(): Each state variable should be called usingself.add_state(...).update(): Any code needed to update the state given any inputs to the metric.compute(): Computes a final value from the state of the metric.
All you need to do is call add_state correctly to implement a custom metric with DDP.
reset() is called on metric state variables added using add_state().
To see how metric states are synchronized across distributed processes, refer to add_state() docs
from the base Metric class.
Example implementation:
from pytorch_lightning.metrics import Metric
class MyAccuracy(Metric):
def __init__(self, dist_sync_on_step=False):
super().__init__(dist_sync_on_step=dist_sync_on_step)
self.add_state("correct", default=torch.tensor(0), dist_reduce_fx="sum")
self.add_state("total", default=torch.tensor(0), dist_reduce_fx="sum")
def update(self, preds: torch.Tensor, target: torch.Tensor):
preds, target = self._input_format(preds, target)
assert preds.shape == target.shape
self.correct += torch.sum(preds == target)
self.total += target.numel()
def compute(self):
return self.correct.float() / self.total
Metrics support backpropagation, if all computations involved in the metric calculation are differentiable. However, note that the cached state is detached from the computational graph and cannot be backpropagated. Not doing this would mean storing the computational graph for each update call, which can lead to out-of-memory errors. In practise this means that:
metric = MyMetric()
val = metric(pred, target) # this value can be backpropagated
val = metric.compute() # this value cannot be backpropagated
Metric API¶
-
class
pytorch_lightning.metrics.Metric(compute_on_step=True, dist_sync_on_step=False, process_group=None, dist_sync_fn=None)[source] Bases:
torch.nn.Module,abc.ABCBase class for all metrics present in the Metrics API.
Implements
add_state(),forward(),reset()and a few other things to handle distributed synchronization and per-step metric computation.Override
update()andcompute()functions to implement your own metric. Useadd_state()to register metric state variables which keep track of state on each call ofupdate()and are synchronized across processes whencompute()is called.Note
Metric state variables can either be
torch.Tensorsor an empty list which can we used to store torch.Tensors`.Note
Different metrics only override
update()and notforward(). A call toupdate()is valid, but it won’t return the metric value at the current step. A call toforward()automatically callsupdate()and also returns the metric value at the current step.- Parameters
compute_on_step¶ (
bool) – Forward only callsupdate()and returns None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step.process_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)dist_sync_fn¶ (
Optional[Callable]) – Callback that performs the allgather operation on the metric state. When None, DDP will be used to perform the allgather. default: None
-
add_state(name, default, dist_reduce_fx=None, persistent=False)[source] Adds metric state variable. Only used by subclasses.
- Parameters
name¶ (
str) – The name of the state variable. The variable will then be accessible atself.name.default¶ – Default value of the state; can either be a
torch.Tensoror an empty list. The state will be reset to this value whenself.reset()is called.dist_reduce_fx¶ (Optional) – Function to reduce state accross mutliple processes in distributed mode. If value is
"sum","mean", or"cat", we will usetorch.sum,torch.mean, andtorch.catrespectively, each with argumentdim=0. Note that the"cat"reduction only makes sense if the state is a list, and not a tensor. The user can also pass a custom function in this parameter.persistent¶ (Optional) – whether the state will be saved as part of the modules
state_dict. Default isFalse.
Note
Setting
dist_reduce_fxto None will return the metric state synchronized across different processes. However, there won’t be any reduction function applied to the synchronized metric state.The metric states would be synced as follows
If the metric state is
torch.Tensor, the synced value will be a stackedtorch.Tensoracross the process dimension if the metric state was atorch.Tensor. The originaltorch.Tensormetric state retains dimension and hence the synchronized output will be of shape(num_process, ...).If the metric state is a
list, the synced value will be alistcontaining the combined elements from all processes.
Note
When passing a custom function to
dist_reduce_fx, expect the synchronized metric state to follow the format discussed in the above note.
-
abstract
compute()[source] Override this method to compute the final metric value from state variables synchronized across the distributed backend.
-
forward(*args, **kwargs)[source] Automatically calls
update(). Returns the metric value over inputs ifcompute_on_stepis True.
-
persistent(mode=False)[source] Method for post-init to change if metric states should be saved to its state_dict
-
reset()[source] This method automatically resets the metric state variables to their default value.
-
abstract
update()[source] Override this method to update the state variables of your metric class.
- Return type
None
Class vs Functional Metrics¶
The functional metrics follow the simple paradigm input in, output out. This means, they don’t provide any advanced mechanisms for syncing across DDP nodes or aggregation over batches. They simply compute the metric value based on the given inputs.
Also, the integration within other parts of PyTorch Lightning will never be as tight as with the class-based interface. If you look for just computing the values, the functional metrics are the way to go. However, if you are looking for the best integration and user experience, please consider also using the class interface.
Classification Metrics¶
Input types¶
For the purposes of classification metrics, inputs (predictions and targets) are split
into these categories (N stands for the batch size and C for number of classes):
Type |
preds shape |
preds dtype |
target shape |
target dtype |
|---|---|---|---|---|
Binary |
(N,) |
|
(N,) |
|
Multi-class |
(N,) |
|
(N,) |
|
Multi-class with probabilities |
(N, C) |
|
(N,) |
|
Multi-label |
(N, …) |
|
(N, …) |
|
Multi-dimensional multi-class |
(N, …) |
|
(N, …) |
|
Multi-dimensional multi-class with probabilities |
(N, C, …) |
|
(N, …) |
|
Note
All dimensions of size 1 (except N) are “squeezed out” at the beginning, so
that, for example, a tensor of shape (N, 1) is treated as (N, ).
When predictions or targets are integers, it is assumed that class labels start at 0, i.e. the possible class labels are 0, 1, 2, 3, etc. Below are some examples of different input types
# Binary inputs
binary_preds = torch.tensor([0.6, 0.1, 0.9])
binary_target = torch.tensor([1, 0, 2])
# Multi-class inputs
mc_preds = torch.tensor([0, 2, 1])
mc_target = torch.tensor([0, 1, 2])
# Multi-class inputs with probabilities
mc_preds_probs = torch.tensor([[0.8, 0.2, 0], [0.1, 0.2, 0.7], [0.3, 0.6, 0.1]])
mc_target_probs = torch.tensor([0, 1, 2])
# Multi-label inputs
ml_preds = torch.tensor([[0.2, 0.8, 0.9], [0.5, 0.6, 0.1], [0.3, 0.1, 0.1]])
ml_target = torch.tensor([[0, 1, 1], [1, 0, 0], [0, 0, 0]])
In some rare cases, you might have inputs which appear to be (multi-dimensional) multi-class but are actually binary/multi-label. For example, if both predictions and targets are 1d binary tensors. Or it could be the other way around, you want to treat binary/multi-label inputs as 2-class (multi-dimensional) multi-class inputs.
For these cases, the metrics where this distinction would make a difference, expose the
is_multiclass argument.
Class Metrics (Classification)¶
Accuracy¶
-
class
pytorch_lightning.metrics.classification.Accuracy(threshold=0.5, compute_on_step=True, dist_sync_on_step=False, process_group=None, dist_sync_fn=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes Accuracy:
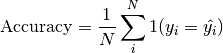
Where
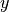 is a tensor of target values, and
is a tensor of target values, and 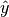 is a
tensor of predictions. Works with binary, multiclass, and multilabel
data. Accepts logits from a model output or integer class values in
prediction. Works with multi-dimensional preds and target.
is a
tensor of predictions. Works with binary, multiclass, and multilabel
data. Accepts logits from a model output or integer class values in
prediction. Works with multi-dimensional preds and target.Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)dist_sync_fn¶ (
Optional[Callable]) – Callback that performs the allgather operation on the metric state. When None, DDP will be used to perform the allgather. default: None
Example
>>> from pytorch_lightning.metrics import Accuracy >>> target = torch.tensor([0, 1, 2, 3]) >>> preds = torch.tensor([0, 2, 1, 3]) >>> accuracy = Accuracy() >>> accuracy(preds, target) tensor(0.5000)
-
compute()[source] Computes accuracy over state.
AveragePrecision¶
-
class
pytorch_lightning.metrics.classification.AveragePrecision(num_classes=None, pos_label=None, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the average precision score, which summarises the precision recall curve into one number. Works for both binary and multiclass problems. In the case of multiclass, the values will be calculated based on a one-vs-the-rest approach.
Forward accepts
preds(float tensor):(N, ...)(binary) or(N, C, ...)(multiclass) where C is the number of classestarget(long tensor):(N, ...)
- Parameters
num_classes¶ (
Optional[int]) – integer with number of classes. Not nessesary to provide for binary problems.pos_label¶ (
Optional[int]) – integer determining the positive class. Default isNonewhich for binary problem is translate to 1. For multiclass problems this argument should not be set as we iteratively change it in the range [0,num_classes-1]compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example (binary case):
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 1, 1]) >>> average_precision = AveragePrecision(pos_label=1) >>> average_precision(pred, target) tensor(1.)
Example (multiclass case):
>>> pred = torch.tensor([[0.75, 0.05, 0.05, 0.05, 0.05], ... [0.05, 0.75, 0.05, 0.05, 0.05], ... [0.05, 0.05, 0.75, 0.05, 0.05], ... [0.05, 0.05, 0.05, 0.75, 0.05]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> average_precision = AveragePrecision(num_classes=5) >>> average_precision(pred, target) [tensor(1.), tensor(1.), tensor(0.2500), tensor(0.2500), tensor(nan)]
-
compute()[source] Compute the average precision score
ConfusionMatrix¶
-
class
pytorch_lightning.metrics.classification.ConfusionMatrix(num_classes, normalize=None, threshold=0.5, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the confusion matrix. Works with binary, multiclass, and multilabel data. Accepts logits from a model output or integer class values in prediction. Works with multi-dimensional preds and target.
Note
This metric produces a multi-dimensional output, so it can not be directly logged.
Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
Normalization mode for confusion matrix. Choose from
None: no normalization (default)'true': normalization over the targets (most commonly used)'pred': normalization over the predictions'all': normalization over the whole matrix
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import ConfusionMatrix >>> target = torch.tensor([1, 1, 0, 0]) >>> preds = torch.tensor([0, 1, 0, 0]) >>> confmat = ConfusionMatrix(num_classes=2) >>> confmat(preds, target) tensor([[2., 0.], [1., 1.]])
F1¶
-
class
pytorch_lightning.metrics.classification.F1(num_classes, threshold=0.5, average='micro', multilabel=False, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.classification.f_beta.FBetaComputes F1 metric. F1 metrics correspond to a harmonic mean of the precision and recall scores.
Works with binary, multiclass, and multilabel data. Accepts logits from a model output or integer class values in prediction. Works with multi-dimensional preds and target.
Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5'micro'computes metric globally'macro'computes metric for each class and uniformly averages them'weighted'computes metric for each class and does a weighted-average, where each class is weighted by their support (accounts for class imbalance)'none'computes and returns the metric per class
multilabel¶ (
bool) – If predictions are from multilabel classification.compute_on_step¶ (
bool) – Forward only callsupdate()and returns None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import F1 >>> target = torch.tensor([0, 1, 2, 0, 1, 2]) >>> preds = torch.tensor([0, 2, 1, 0, 0, 1]) >>> f1 = F1(num_classes=3) >>> f1(preds, target) tensor(0.3333)
FBeta¶
-
class
pytorch_lightning.metrics.classification.FBeta(num_classes, beta=1.0, threshold=0.5, average='micro', multilabel=False, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes F-score, specifically:
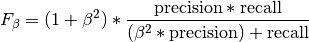
Where
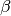 is some positive real factor. Works with binary, multiclass, and multilabel data.
Accepts logits from a model output or integer class values in prediction.
Works with multi-dimensional preds and target.
is some positive real factor. Works with binary, multiclass, and multilabel data.
Accepts logits from a model output or integer class values in prediction.
Works with multi-dimensional preds and target.Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5'micro'computes metric globally'macro'computes metric for each class and uniformly averages them'weighted'computes metric for each class and does a weighted-average, where each class is weighted by their support (accounts for class imbalance)'none'computes and returns the metric per class
multilabel¶ (
bool) – If predictions are from multilabel classification.compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import FBeta >>> target = torch.tensor([0, 1, 2, 0, 1, 2]) >>> preds = torch.tensor([0, 2, 1, 0, 0, 1]) >>> f_beta = FBeta(num_classes=3, beta=0.5) >>> f_beta(preds, target) tensor(0.3333)
Precision¶
-
class
pytorch_lightning.metrics.classification.Precision(num_classes=1, threshold=0.5, average='micro', multilabel=False, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes Precision:
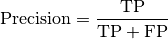
Where
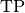 and
and 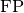 represent the number of true positives and
false positives respecitively. Works with binary, multiclass, and
multilabel data. Accepts logits from a model output or integer class
values in prediction. Works with multi-dimensional preds and target.
represent the number of true positives and
false positives respecitively. Works with binary, multiclass, and
multilabel data. Accepts logits from a model output or integer class
values in prediction. Works with multi-dimensional preds and target.Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5‘micro’ computes metric globally
’macro’ computes metric for each class and then takes the mean
multilabel¶ (
bool) – If predictions are from multilabel classification.compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import Precision >>> target = torch.tensor([0, 1, 2, 0, 1, 2]) >>> preds = torch.tensor([0, 2, 1, 0, 0, 1]) >>> precision = Precision(num_classes=3) >>> precision(preds, target) tensor(0.3333)
-
compute()[source] Override this method to compute the final metric value from state variables synchronized across the distributed backend.
-
update(preds, target)[source] Override this method to update the state variables of your metric class.
PrecisionRecallCurve¶
-
class
pytorch_lightning.metrics.classification.PrecisionRecallCurve(num_classes=None, pos_label=None, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes precision-recall pairs for different thresholds. Works for both binary and multiclass problems. In the case of multiclass, the values will be calculated based on a one-vs-the-rest approach.
Forward accepts
preds(float tensor):(N, ...)(binary) or(N, C, ...)(multiclass) where C is the number of classestarget(long tensor):(N, ...)
- Parameters
num_classes¶ (
Optional[int]) – integer with number of classes. Not nessesary to provide for binary problems.pos_label¶ (
Optional[int]) – integer determining the positive class. Default isNonewhich for binary problem is translate to 1. For multiclass problems this argument should not be set as we iteratively change it in the range [0,num_classes-1]compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example (binary case):
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 1, 0]) >>> pr_curve = PrecisionRecallCurve(pos_label=1) >>> precision, recall, thresholds = pr_curve(pred, target) >>> precision tensor([0.6667, 0.5000, 0.0000, 1.0000]) >>> recall tensor([1.0000, 0.5000, 0.0000, 0.0000]) >>> thresholds tensor([1, 2, 3])
Example (multiclass case):
>>> pred = torch.tensor([[0.75, 0.05, 0.05, 0.05, 0.05], ... [0.05, 0.75, 0.05, 0.05, 0.05], ... [0.05, 0.05, 0.75, 0.05, 0.05], ... [0.05, 0.05, 0.05, 0.75, 0.05]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> pr_curve = PrecisionRecallCurve(num_classes=5) >>> precision, recall, thresholds = pr_curve(pred, target) >>> precision [tensor([1., 1.]), tensor([1., 1.]), tensor([0.2500, 0.0000, 1.0000]), tensor([0.2500, 0.0000, 1.0000]), tensor([0., 1.])] >>> recall [tensor([1., 0.]), tensor([1., 0.]), tensor([1., 0., 0.]), tensor([1., 0., 0.]), tensor([nan, 0.])] >>> thresholds [tensor([0.7500]), tensor([0.7500]), tensor([0.0500, 0.7500]), tensor([0.0500, 0.7500]), tensor([0.0500])]
-
compute()[source] Compute the precision-recall curve
Returns: 3-element tuple containing
- precision:
tensor where element i is the precision of predictions with score >= thresholds[i] and the last element is 1. If multiclass, this is a list of such tensors, one for each class.
- recall:
tensor where element i is the recall of predictions with score >= thresholds[i] and the last element is 0. If multiclass, this is a list of such tensors, one for each class.
- thresholds:
Thresholds used for computing precision/recall scores
Recall¶
-
class
pytorch_lightning.metrics.classification.Recall(num_classes=1, threshold=0.5, average='micro', multilabel=False, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes Recall:
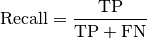
Where
and 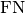 represent the number of true positives and
false negatives respecitively. Works with binary, multiclass, and
multilabel data. Accepts logits from a model output or integer class
values in prediction. Works with multi-dimensional preds and target.
represent the number of true positives and
false negatives respecitively. Works with binary, multiclass, and
multilabel data. Accepts logits from a model output or integer class
values in prediction. Works with multi-dimensional preds and target.Forward accepts
preds(float or long tensor):(N, ...)or(N, C, ...)where C is the number of classestarget(long tensor):(N, ...)
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5‘micro’ computes metric globally
’macro’ computes metric for each class and then takes the mean
multilabel¶ (
bool) – If predictions are from multilabel classification.compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import Recall >>> target = torch.tensor([0, 1, 2, 0, 1, 2]) >>> preds = torch.tensor([0, 2, 1, 0, 0, 1]) >>> recall = Recall(num_classes=3) >>> recall(preds, target) tensor(0.3333)
-
compute()[source] Computes recall over state.
ROC¶
-
class
pytorch_lightning.metrics.classification.ROC(num_classes=None, pos_label=None, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes the Receiver Operating Characteristic (ROC). Works for both binary and multiclass problems. In the case of multiclass, the values will be calculated based on a one-vs-the-rest approach.
Forward accepts
preds(float tensor):(N, ...)(binary) or(N, C, ...)(multiclass) where C is the number of classestarget(long tensor):(N, ...)
- Parameters
num_classes¶ (
Optional[int]) – integer with number of classes. Not nessesary to provide for binary problems.pos_label¶ (
Optional[int]) – integer determining the positive class. Default isNonewhich for binary problem is translate to 1. For multiclass problems this argument should not be set as we iteratively change it in the range [0,num_classes-1]compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example (binary case):
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 1, 1]) >>> roc = ROC(pos_label=1) >>> fpr, tpr, thresholds = roc(pred, target) >>> fpr tensor([0., 0., 0., 0., 1.]) >>> tpr tensor([0.0000, 0.3333, 0.6667, 1.0000, 1.0000]) >>> thresholds tensor([4, 3, 2, 1, 0])
Example (multiclass case):
>>> pred = torch.tensor([[0.75, 0.05, 0.05, 0.05], ... [0.05, 0.75, 0.05, 0.05], ... [0.05, 0.05, 0.75, 0.05], ... [0.05, 0.05, 0.05, 0.75]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> roc = ROC(num_classes=4) >>> fpr, tpr, thresholds = roc(pred, target) >>> fpr [tensor([0., 0., 1.]), tensor([0., 0., 1.]), tensor([0.0000, 0.3333, 1.0000]), tensor([0.0000, 0.3333, 1.0000])] >>> tpr [tensor([0., 1., 1.]), tensor([0., 1., 1.]), tensor([0., 0., 1.]), tensor([0., 0., 1.])] >>> thresholds [tensor([1.7500, 0.7500, 0.0500]), tensor([1.7500, 0.7500, 0.0500]), tensor([1.7500, 0.7500, 0.0500]), tensor([1.7500, 0.7500, 0.0500])]
-
compute()[source] Compute the receiver operating characteristic
Returns: 3-element tuple containing
- fpr:
tensor with false positive rates. If multiclass, this is a list of such tensors, one for each class.
- tpr:
tensor with true positive rates. If multiclass, this is a list of such tensors, one for each class.
- thresholds:
thresholds used for computing false- and true postive rates
Functional Metrics (Classification)¶
accuracy [func]¶
-
pytorch_lightning.metrics.functional.classification.accuracy(pred, target, num_classes=None, class_reduction='micro', return_state=False)[source] Computes the accuracy classification score
- Parameters
method to reduce metric score over labels
'micro': calculate metrics globally (default)'macro': calculate metrics for each label, and find their unweighted mean.'weighted': calculate metrics for each label, and find their weighted mean.'none': returns calculated metric per class
return_state¶ (
bool) – returns a internal state that can be ddp reduced before doing the final calculation
- Return type
- Returns
A Tensor with the accuracy score.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> accuracy(x, y) tensor(0.7500)
auc [func]¶
-
pytorch_lightning.metrics.functional.classification.auc(x, y)[source] Computes Area Under the Curve (AUC) using the trapezoidal rule
- Parameters
- Return type
- Returns
Tensor containing AUC score (float)
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> auc(x, y) tensor(4.)
auroc [func]¶
-
pytorch_lightning.metrics.functional.classification.auroc(pred, target, sample_weight=None, pos_label=1.0)[source] Compute Area Under the Receiver Operating Characteristic Curve (ROC AUC) from prediction scores
- Parameters
- Return type
- Returns
Tensor containing ROCAUC score
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 1, 0]) >>> auroc(x, y) tensor(0.5000)
multiclass_auroc [func]¶
-
pytorch_lightning.metrics.functional.classification.multiclass_auroc(pred, target, sample_weight=None, num_classes=None)[source] Compute Area Under the Receiver Operating Characteristic Curve (ROC AUC) from multiclass prediction scores
- Parameters
- Return type
- Returns
Tensor containing ROCAUC score
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> multiclass_auroc(pred, target, num_classes=4) tensor(0.6667)
average_precision [func]¶
-
pytorch_lightning.metrics.functional.average_precision(preds, target, num_classes=None, pos_label=None, sample_weights=None)[source] Computes the average precision score.
- Parameters
num_classes¶ (
Optional[int]) – integer with number of classes. Not nessesary to provide for binary problems.pos_label¶ (
Optional[int]) – integer determining the positive class. Default isNonewhich for binary problem is translate to 1. For multiclass problems this argument should not be set as we iteratively change it in the range [0,num_classes-1]sample_weight¶ – sample weights for each data point
- Return type
- Returns
tensor with average precision. If multiclass will return list of such tensors, one for each class
Example (binary case):
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 1, 1]) >>> average_precision(pred, target, pos_label=1) tensor(1.)
Example (multiclass case):
>>> pred = torch.tensor([[0.75, 0.05, 0.05, 0.05, 0.05], ... [0.05, 0.75, 0.05, 0.05, 0.05], ... [0.05, 0.05, 0.75, 0.05, 0.05], ... [0.05, 0.05, 0.05, 0.75, 0.05]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> average_precision(pred, target, num_classes=5) [tensor(1.), tensor(1.), tensor(0.2500), tensor(0.2500), tensor(nan)]
confusion_matrix [func]¶
-
pytorch_lightning.metrics.functional.confusion_matrix(preds, target, num_classes, normalize=None, threshold=0.5)[source] Computes the confusion matrix. Works with binary, multiclass, and multilabel data. Accepts logits from a model output or integer class values in prediction. Works with multi-dimensional preds and target.
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
preds¶ (
Tensor) – (float or long tensor), Either a(N, ...)tensor with labels or(N, C, ...)where C is the number of classes, tensor with logits/probabilitiestarget¶ (
Tensor) –target(long tensor), tensor with shape(N, ...)with ground true labelsNormalization mode for confusion matrix. Choose from
None: no normalization (default)'true': normalization over the targets (most commonly used)'pred': normalization over the predictions'all': normalization over the whole matrix
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5
Example
>>> from pytorch_lightning.metrics.functional import confusion_matrix >>> target = torch.tensor([1, 1, 0, 0]) >>> preds = torch.tensor([0, 1, 0, 0]) >>> confusion_matrix(preds, target, num_classes=2) tensor([[2., 0.], [1., 1.]])
- Return type
dice_score [func]¶
-
pytorch_lightning.metrics.functional.classification.dice_score(pred, target, bg=False, nan_score=0.0, no_fg_score=0.0, reduction='elementwise_mean')[source] Compute dice score from prediction scores
- Parameters
bg¶ (
bool) – whether to also compute dice for the backgroundnan_score¶ (
float) – score to return, if a NaN occurs during computationno_fg_score¶ (
float) – score to return, if no foreground pixel was found in targeta method to reduce metric score over labels.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none': no reduction will be applied
- Return type
- Returns
Tensor containing dice score
Example
>>> pred = torch.tensor([[0.85, 0.05, 0.05, 0.05], ... [0.05, 0.85, 0.05, 0.05], ... [0.05, 0.05, 0.85, 0.05], ... [0.05, 0.05, 0.05, 0.85]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> dice_score(pred, target) tensor(0.3333)
f1 [func]¶
-
pytorch_lightning.metrics.functional.f1(preds, target, num_classes, threshold=0.5, average='micro', multilabel=False)[source] Computes F1 metric. F1 metrics correspond to a equally weighted average of the precision and recall scores.
Works with binary, multiclass, and multilabel data. Accepts logits from a model output or integer class values in prediction. Works with multi-dimensional preds and target.
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
pred¶ – estimated probabilities
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5'micro'computes metric globally'macro'computes metric for each class and uniformly averages them'weighted'computes metric for each class and does a weighted-average, where each class is weighted by their support (accounts for class imbalance)'none'computes and returns the metric per class
multilabel¶ (
bool) – If predictions are from multilabel classification.
Example
>>> from pytorch_lightning.metrics.functional import f1 >>> target = torch.tensor([0, 1, 2, 0, 1, 2]) >>> preds = torch.tensor([0, 2, 1, 0, 0, 1]) >>> f1(preds, target, num_classes=3) tensor(0.3333)
- Return type
fbeta [func]¶
-
pytorch_lightning.metrics.functional.fbeta(preds, target, num_classes, beta=1.0, threshold=0.5, average='micro', multilabel=False)[source] Computes f_beta metric.
Works with binary, multiclass, and multilabel data. Accepts logits from a model output or integer class values in prediction. Works with multi-dimensional preds and target.
If preds and target are the same shape and preds is a float tensor, we use the
self.thresholdargument. This is the case for binary and multi-label logits.If preds has an extra dimension as in the case of multi-class scores we perform an argmax on
dim=1.- Parameters
pred¶ – estimated probabilities
threshold¶ (
float) – Threshold value for binary or multi-label logits. default: 0.5'micro'computes metric globally'macro'computes metric for each class and uniformly averages them'weighted'computes metric for each class and does a weighted-average, where each class is weighted by their support (accounts for class imbalance)'none'computes and returns the metric per class
multilabel¶ (
bool) – If predictions are from multilabel classification.
Example
>>> from pytorch_lightning.metrics.functional import fbeta >>> target = torch.tensor([0, 1, 2, 0, 1, 2]) >>> preds = torch.tensor([0, 2, 1, 0, 0, 1]) >>> fbeta(preds, target, num_classes=3, beta=0.5) tensor(0.3333)
- Return type
iou [func]¶
-
pytorch_lightning.metrics.functional.classification.iou(pred, target, ignore_index=None, absent_score=0.0, num_classes=None, reduction='elementwise_mean')[source] Intersection over union, or Jaccard index calculation.
- Parameters
pred¶ (
Tensor) – Tensor containing integer predictions, with shape [N, d1, d2, …]target¶ (
Tensor) – Tensor containing integer targets, with shape [N, d1, d2, …]ignore_index¶ (
Optional[int]) – optional int specifying a target class to ignore. If given, this class index does not contribute to the returned score, regardless of reduction method. Has no effect if given an int that is not in the range [0, num_classes-1], where num_classes is either given or derived from pred and target. By default, no index is ignored, and all classes are used.absent_score¶ (
float) – score to use for an individual class, if no instances of the class index were present in pred AND no instances of the class index were present in target. For example, if we have 3 classes, [0, 0] for pred, and [0, 2] for target, then class 1 would be assigned the absent_score. Default is 0.0.num_classes¶ (
Optional[int]) – Optionally specify the number of classesa method to reduce metric score over labels.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none': no reduction will be applied
- Returns
Tensor containing single value if reduction is ‘elementwise_mean’, or number of classes if reduction is ‘none’
- Return type
IoU score
Example
>>> target = torch.randint(0, 2, (10, 25, 25)) >>> pred = torch.tensor(target) >>> pred[2:5, 7:13, 9:15] = 1 - pred[2:5, 7:13, 9:15] >>> iou(pred, target) tensor(0.9660)
roc [func]¶
-
pytorch_lightning.metrics.functional.roc(preds, target, num_classes=None, pos_label=None, sample_weights=None)[source] Computes the Receiver Operating Characteristic (ROC).
- Parameters
num_classes¶ (
Optional[int]) – integer with number of classes. Not nessesary to provide for binary problems.pos_label¶ (
Optional[int]) – integer determining the positive class. Default isNonewhich for binary problem is translate to 1. For multiclass problems this argument should not be set as we iteratively change it in the range [0,num_classes-1]sample_weight¶ – sample weights for each data point
Returns: 3-element tuple containing
- fpr:
tensor with false positive rates. If multiclass, this is a list of such tensors, one for each class.
- tpr:
tensor with true positive rates. If multiclass, this is a list of such tensors, one for each class.
- thresholds:
thresholds used for computing false- and true postive rates
Example (binary case):
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 1, 1]) >>> fpr, tpr, thresholds = roc(pred, target, pos_label=1) >>> fpr tensor([0., 0., 0., 0., 1.]) >>> tpr tensor([0.0000, 0.3333, 0.6667, 1.0000, 1.0000]) >>> thresholds tensor([4, 3, 2, 1, 0])
Example (multiclass case):
>>> pred = torch.tensor([[0.75, 0.05, 0.05, 0.05], ... [0.05, 0.75, 0.05, 0.05], ... [0.05, 0.05, 0.75, 0.05], ... [0.05, 0.05, 0.05, 0.75]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> fpr, tpr, thresholds = roc(pred, target, num_classes=4) >>> fpr [tensor([0., 0., 1.]), tensor([0., 0., 1.]), tensor([0.0000, 0.3333, 1.0000]), tensor([0.0000, 0.3333, 1.0000])] >>> tpr [tensor([0., 1., 1.]), tensor([0., 1., 1.]), tensor([0., 0., 1.]), tensor([0., 0., 1.])] >>> thresholds [tensor([1.7500, 0.7500, 0.0500]), tensor([1.7500, 0.7500, 0.0500]), tensor([1.7500, 0.7500, 0.0500]), tensor([1.7500, 0.7500, 0.0500])]
precision [func]¶
-
pytorch_lightning.metrics.functional.classification.precision(pred, target, num_classes=None, class_reduction='micro')[source] Computes precision score.
- Parameters
method to reduce metric score over labels
'micro': calculate metrics globally (default)'macro': calculate metrics for each label, and find their unweighted mean.'weighted': calculate metrics for each label, and find their weighted mean.'none': returns calculated metric per class
- Return type
- Returns
Tensor with precision.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> precision(x, y) tensor(0.7500)
precision_recall [func]¶
-
pytorch_lightning.metrics.functional.classification.precision_recall(pred, target, num_classes=None, class_reduction='micro', return_support=False, return_state=False)[source] Computes precision and recall for different thresholds
- Parameters
method to reduce metric score over labels
'micro': calculate metrics globally (default)'macro': calculate metrics for each label, and find their unweighted mean.'weighted': calculate metrics for each label, and find their weighted mean.'none': returns calculated metric per class
return_support¶ (
bool) – returns the support for each class, need for fbeta/f1 calculationsreturn_state¶ (
bool) – returns a internal state that can be ddp reduced before doing the final calculation
- Return type
- Returns
Tensor with precision and recall
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 2, 2, 2]) >>> precision_recall(x, y, class_reduction='macro') (tensor(0.5000), tensor(0.3333))
precision_recall_curve [func]¶
-
pytorch_lightning.metrics.functional.precision_recall_curve(preds, target, num_classes=None, pos_label=None, sample_weights=None)[source] Computes precision-recall pairs for different thresholds.
- Parameters
num_classes¶ (
Optional[int]) – integer with number of classes. Not nessesary to provide for binary problems.pos_label¶ (
Optional[int]) – integer determining the positive class. Default isNonewhich for binary problem is translate to 1. For multiclass problems this argument should not be set as we iteratively change it in the range [0,num_classes-1]sample_weight¶ – sample weights for each data point
Returns: 3-element tuple containing
- precision:
tensor where element i is the precision of predictions with score >= thresholds[i] and the last element is 1. If multiclass, this is a list of such tensors, one for each class.
- recall:
tensor where element i is the recall of predictions with score >= thresholds[i] and the last element is 0. If multiclass, this is a list of such tensors, one for each class.
- thresholds:
Thresholds used for computing precision/recall scores
Example (binary case):
>>> pred = torch.tensor([0, 1, 2, 3]) >>> target = torch.tensor([0, 1, 1, 0]) >>> precision, recall, thresholds = precision_recall_curve(pred, target, pos_label=1) >>> precision tensor([0.6667, 0.5000, 0.0000, 1.0000]) >>> recall tensor([1.0000, 0.5000, 0.0000, 0.0000]) >>> thresholds tensor([1, 2, 3])
Example (multiclass case):
>>> pred = torch.tensor([[0.75, 0.05, 0.05, 0.05, 0.05], ... [0.05, 0.75, 0.05, 0.05, 0.05], ... [0.05, 0.05, 0.75, 0.05, 0.05], ... [0.05, 0.05, 0.05, 0.75, 0.05]]) >>> target = torch.tensor([0, 1, 3, 2]) >>> precision, recall, thresholds = precision_recall_curve(pred, target, num_classes=5) >>> precision [tensor([1., 1.]), tensor([1., 1.]), tensor([0.2500, 0.0000, 1.0000]), tensor([0.2500, 0.0000, 1.0000]), tensor([0., 1.])] >>> recall [tensor([1., 0.]), tensor([1., 0.]), tensor([1., 0., 0.]), tensor([1., 0., 0.]), tensor([nan, 0.])] >>> thresholds [tensor([0.7500]), tensor([0.7500]), tensor([0.0500, 0.7500]), tensor([0.0500, 0.7500]), tensor([0.0500])]
recall [func]¶
-
pytorch_lightning.metrics.functional.classification.recall(pred, target, num_classes=None, class_reduction='micro')[source] Computes recall score.
- Parameters
method to reduce metric score over labels
'micro': calculate metrics globally (default)'macro': calculate metrics for each label, and find their unweighted mean.'weighted': calculate metrics for each label, and find their weighted mean.'none': returns calculated metric per class
- Return type
- Returns
Tensor with recall.
Example
>>> x = torch.tensor([0, 1, 2, 3]) >>> y = torch.tensor([0, 1, 2, 2]) >>> recall(x, y) tensor(0.7500)
select_topk [func]¶
-
pytorch_lightning.metrics.utils.select_topk(prob_tensor, topk=1, dim=1)[source] Convert a probability tensor to binary by selecting top-k highest entries.
- Parameters
- Output:
A binary tensor of the same shape as the input tensor of type torch.int32
Example
>>> x = torch.tensor([[1.1, 2.0, 3.0], [2.0, 1.0, 0.5]]) >>> select_topk(x, topk=2) tensor([[0, 1, 1], [1, 1, 0]], dtype=torch.int32)
- Return type
stat_scores [func]¶
-
pytorch_lightning.metrics.functional.classification.stat_scores(pred, target, class_index, argmax_dim=1)[source] Calculates the number of true positive, false positive, true negative and false negative for a specific class
- Parameters
- Return type
- Returns
True Positive, False Positive, True Negative, False Negative, Support
Example
>>> x = torch.tensor([1, 2, 3]) >>> y = torch.tensor([0, 2, 3]) >>> tp, fp, tn, fn, sup = stat_scores(x, y, class_index=1) >>> tp, fp, tn, fn, sup (tensor(0), tensor(1), tensor(2), tensor(0), tensor(0))
stat_scores_multiple_classes [func]¶
-
pytorch_lightning.metrics.functional.classification.stat_scores_multiple_classes(pred, target, num_classes=None, argmax_dim=1, reduction='none')[source] Calculates the number of true positive, false positive, true negative and false negative for each class
- Parameters
- Return type
- Returns
True Positive, False Positive, True Negative, False Negative, Support
Example
>>> x = torch.tensor([1, 2, 3]) >>> y = torch.tensor([0, 2, 3]) >>> tps, fps, tns, fns, sups = stat_scores_multiple_classes(x, y) >>> tps tensor([0., 0., 1., 1.]) >>> fps tensor([0., 1., 0., 0.]) >>> tns tensor([2., 2., 2., 2.]) >>> fns tensor([1., 0., 0., 0.]) >>> sups tensor([1., 0., 1., 1.])
to_categorical [func]¶
-
pytorch_lightning.metrics.utils.to_categorical(tensor, argmax_dim=1)[source] Converts a tensor of probabilities to a dense label tensor
- Parameters
- Return type
- Returns
A tensor with categorical labels [N, d2, …]
Example
>>> x = torch.tensor([[0.2, 0.5], [0.9, 0.1]]) >>> to_categorical(x) tensor([1, 0])
to_onehot [func]¶
-
pytorch_lightning.metrics.utils.to_onehot(label_tensor, num_classes=None)[source] Converts a dense label tensor to one-hot format
- Parameters
- Output:
A sparse label tensor with shape [N, C, d1, d2, …]
Example
>>> x = torch.tensor([1, 2, 3]) >>> to_onehot(x) tensor([[0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
- Return type
Regression Metrics¶
Class Metrics (Regression)¶
ExplainedVariance¶
-
class
pytorch_lightning.metrics.regression.ExplainedVariance(multioutput='uniform_average', compute_on_step=True, dist_sync_on_step=False, process_group=None, dist_sync_fn=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes explained variance:
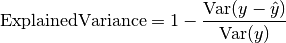
Where
is a tensor of target values, and is a
tensor of predictions.Forward accepts
preds(float tensor):(N,)or(N, ...)(multioutput)target(long tensor):(N,)or(N, ...)(multioutput)
In the case of multioutput, as default the variances will be uniformly averaged over the additional dimensions. Please see argument multioutput for changing this behavior.
- Parameters
Defines aggregation in the case of multiple output scores. Can be one of the following strings (default is ‘uniform_average’.):
’raw_values’ returns full set of scores
’uniform_average’ scores are uniformly averaged
’variance_weighted’ scores are weighted by their individual variances
compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import ExplainedVariance >>> target = torch.tensor([3, -0.5, 2, 7]) >>> preds = torch.tensor([2.5, 0.0, 2, 8]) >>> explained_variance = ExplainedVariance() >>> explained_variance(preds, target) tensor(0.9572)
>>> target = torch.tensor([[0.5, 1], [-1, 1], [7, -6]]) >>> preds = torch.tensor([[0, 2], [-1, 2], [8, -5]]) >>> explained_variance = ExplainedVariance(multioutput='raw_values') >>> explained_variance(preds, target) tensor([0.9677, 1.0000])
-
compute()[source] Computes explained variance over state.
MeanAbsoluteError¶
-
class
pytorch_lightning.metrics.regression.MeanAbsoluteError(compute_on_step=True, dist_sync_on_step=False, process_group=None, dist_sync_fn=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes mean absolute error (MAE):
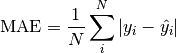
Where
is a tensor of target values, and is a tensor of predictions.- Parameters
compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import MeanAbsoluteError >>> target = torch.tensor([3.0, -0.5, 2.0, 7.0]) >>> preds = torch.tensor([2.5, 0.0, 2.0, 8.0]) >>> mean_absolute_error = MeanAbsoluteError() >>> mean_absolute_error(preds, target) tensor(0.5000)
-
compute()[source] Computes mean absolute error over state.
MeanSquaredError¶
-
class
pytorch_lightning.metrics.regression.MeanSquaredError(compute_on_step=True, dist_sync_on_step=False, process_group=None, dist_sync_fn=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes mean squared error (MSE):
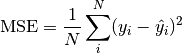
Where
is a tensor of target values, and is a tensor of predictions.- Parameters
compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import MeanSquaredError >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0]) >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0]) >>> mean_squared_error = MeanSquaredError() >>> mean_squared_error(preds, target) tensor(0.8750)
-
compute()[source] Computes mean squared error over state.
MeanSquaredLogError¶
-
class
pytorch_lightning.metrics.regression.MeanSquaredLogError(compute_on_step=True, dist_sync_on_step=False, process_group=None, dist_sync_fn=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes mean squared logarithmic error (MSLE):
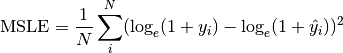
Where
is a tensor of target values, and is a tensor of predictions.- Parameters
compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import MeanSquaredLogError >>> target = torch.tensor([2.5, 5, 4, 8]) >>> preds = torch.tensor([3, 5, 2.5, 7]) >>> mean_squared_log_error = MeanSquaredLogError() >>> mean_squared_log_error(preds, target) tensor(0.0397)
-
compute()[source] Compute mean squared logarithmic error over state.
PSNR¶
-
class
pytorch_lightning.metrics.regression.PSNR(data_range=None, base=10.0, reduction='elementwise_mean', compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes peak signal-to-noise ratio (PSNR):
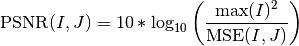
Where
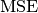 denotes the mean-squared-error function.
denotes the mean-squared-error function.- Parameters
data_range¶ (
Optional[float]) – the range of the data. If None, it is determined from the data (max - min)a method to reduce metric score over labels.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none': no reduction will be applied
compute_on_step¶ (
bool) – Forward only callsupdate()and return None if this is set to False. default: Truedist_sync_on_step¶ (
bool) – Synchronize metric state across processes at eachforward()before returning the value at the step. default: Falseprocess_group¶ (
Optional[Any]) – Specify the process group on which synchronization is called. default: None (which selects the entire world)
Example
>>> from pytorch_lightning.metrics import PSNR >>> psnr = PSNR() >>> preds = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) >>> target = torch.tensor([[3.0, 2.0], [1.0, 0.0]]) >>> psnr(preds, target) tensor(2.5527)
-
compute()[source] Compute peak signal-to-noise ratio over state.
SSIM¶
-
class
pytorch_lightning.metrics.regression.SSIM(kernel_size=(11, 11), sigma=(1.5, 1.5), reduction='elementwise_mean', data_range=None, k1=0.01, k2=0.03, compute_on_step=True, dist_sync_on_step=False, process_group=None)[source] Bases:
pytorch_lightning.metrics.metric.MetricComputes Structual Similarity Index Measure (SSIM).
- Parameters
kernel_size¶ (
Sequence[int]) – size of the gaussian kernel (default: (11, 11))sigma¶ (
Sequence[float]) – Standard deviation of the gaussian kernel (default: (1.5, 1.5))a method to reduce metric score over labels.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none': no reduction will be applied
data_range¶ (
Optional[float]) – Range of the image. IfNone, it is determined from the image (max - min)
- Returns
Tensor with SSIM score
Example
>>> from pytorch_lightning.metrics import SSIM >>> preds = torch.rand([16, 1, 16, 16]) >>> target = preds * 0.75 >>> ssim = SSIM() >>> ssim(preds, target) tensor(0.9219)
-
compute()[source] Computes explained variance over state.
Functional Metrics (Regression)¶
explained_variance [func]¶
-
pytorch_lightning.metrics.functional.explained_variance(preds, target, multioutput='uniform_average')[source] Computes explained variance.
- Parameters
pred¶ – estimated labels
Defines aggregation in the case of multiple output scores. Can be one of the following strings (default is ‘uniform_average’.):
’raw_values’ returns full set of scores
’uniform_average’ scores are uniformly averaged
’variance_weighted’ scores are weighted by their individual variances
Example
>>> from pytorch_lightning.metrics.functional import explained_variance >>> target = torch.tensor([3, -0.5, 2, 7]) >>> preds = torch.tensor([2.5, 0.0, 2, 8]) >>> explained_variance(preds, target) tensor(0.9572)
>>> target = torch.tensor([[0.5, 1], [-1, 1], [7, -6]]) >>> preds = torch.tensor([[0, 2], [-1, 2], [8, -5]]) >>> explained_variance(preds, target, multioutput='raw_values') tensor([0.9677, 1.0000])
mean_absolute_error [func]¶
-
pytorch_lightning.metrics.functional.mean_absolute_error(preds, target)[source] Computes mean absolute error
- Parameters
- Return type
- Returns
Tensor with MAE
Example
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> mean_absolute_error(x, y) tensor(0.2500)
mean_squared_error [func]¶
-
pytorch_lightning.metrics.functional.mean_squared_error(preds, target)[source] Computes mean squared error
- Parameters
- Return type
- Returns
Tensor with MSE
Example
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> mean_squared_error(x, y) tensor(0.2500)
mean_squared_log_error [func]¶
-
pytorch_lightning.metrics.functional.mean_squared_log_error(preds, target)[source] Computes mean squared log error
- Parameters
- Return type
- Returns
Tensor with RMSLE
Example
>>> x = torch.tensor([0., 1, 2, 3]) >>> y = torch.tensor([0., 1, 2, 2]) >>> mean_squared_log_error(x, y) tensor(0.0207)
psnr [func]¶
-
pytorch_lightning.metrics.functional.psnr(preds, target, data_range=None, base=10.0, reduction='elementwise_mean')[source] Computes the peak signal-to-noise ratio
- Parameters
data_range¶ (
Optional[float]) – the range of the data. If None, it is determined from the data (max - min)a method to reduce metric score over labels.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none': no reduction will be applied
return_state¶ – returns a internal state that can be ddp reduced before doing the final calculation
- Return type
- Returns
Tensor with PSNR score
Example
>>> pred = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) >>> target = torch.tensor([[3.0, 2.0], [1.0, 0.0]]) >>> psnr(pred, target) tensor(2.5527)
ssim [func]¶
-
pytorch_lightning.metrics.functional.ssim(preds, target, kernel_size=(11, 11), sigma=(1.5, 1.5), reduction='elementwise_mean', data_range=None, k1=0.01, k2=0.03)[source] Computes Structual Similarity Index Measure
- Parameters
pred¶ – estimated image
kernel_size¶ (
Sequence[int]) – size of the gaussian kernel (default: (11, 11))sigma¶ (
Sequence[float]) – Standard deviation of the gaussian kernel (default: (1.5, 1.5))a method to reduce metric score over labels.
'elementwise_mean': takes the mean (default)'sum': takes the sum'none': no reduction will be applied
data_range¶ (
Optional[float]) – Range of the image. IfNone, it is determined from the image (max - min)
- Return type
- Returns
Tensor with SSIM score
Example
>>> preds = torch.rand([16, 1, 16, 16]) >>> target = preds * 0.75 >>> ssim(preds, target) tensor(0.9219)
NLP¶
bleu_score [func]¶
-
pytorch_lightning.metrics.functional.nlp.bleu_score(translate_corpus, reference_corpus, n_gram=4, smooth=False)[source] Calculate BLEU score of machine translated text with one or more references
- Parameters
- Return type
- Returns
Tensor with BLEU Score
Example
>>> translate_corpus = ['the cat is on the mat'.split()] >>> reference_corpus = [['there is a cat on the mat'.split(), 'a cat is on the mat'.split()]] >>> bleu_score(translate_corpus, reference_corpus) tensor(0.7598)
Pairwise¶
embedding_similarity [func]¶
-
pytorch_lightning.metrics.functional.self_supervised.embedding_similarity(batch, similarity='cosine', reduction='none', zero_diagonal=True)[source] Computes representation similarity
Example
>>> embeddings = torch.tensor([[1., 2., 3., 4.], [1., 2., 3., 4.], [4., 5., 6., 7.]]) >>> embedding_similarity(embeddings) tensor([[0.0000, 1.0000, 0.9759], [1.0000, 0.0000, 0.9759], [0.9759, 0.9759, 0.0000]])
- Parameters
- Return type
- Returns
A square matrix (batch, batch) with the similarity scores between all elements If sum or mean are used, then returns (b, 1) with the reduced value for each row
